Linux
- Podstawowe komendy użytkowe
- Poruszanie się w CLI / BASH / SSH
- Obsługa przegladania plików : CAT, HEAD, TAIL
- Obsługa komendy "ps" - Proces Status
- Monitorowanie procesów na żywo: top i htop
- Zaawansowane wyszukiwanie z użyciem find i grep
- Obsługa dysków i systemów plików: df, du, lsblk, lscsi
- Linki symboliczne i twarde w systemach Linux/Unix
- Monitorowanie zasobów: free, vmstat, iostat, sara
- Uprawnienia plików i katalogów - chmod i chowa
- Atrybuty plików i katalogów
- Obsługa komendy sed
- Obsługa awk
- Ogólne komendy BASH
- Sprawdzanie zombie procesów
- Czyszczenie SWAP
- Sprawdzenie czy user może korzystać z sudo
- Sprawdzenie daty wygasania hasła użytkownika
- Sieć
- Przekierowanie ruchu sieciowego pomiędzy kartami sieciowymi
- Skrypt tworzący reguły przekierowania dla portów mailowych
- Weryfikacja zapory sieciowej (firewalld) oraz dodanie wyjątków
- Specyficzne dla Rodziny Enterprise Linux
- Usunięcie nieużywanych kerneli
- Ręczna instalacja repozytorium EPEL (Extra Packages for Enterprise Linux)
- Podział aktualizacji pakietów pod względem nazw pakietów
- Doinstalowanie obsługi SysV na Rocky 9
- Instalacja systemu Rocky Linux 9 z nazwaniem odpowiednio VG oraz LV
- Kolororwanie BASH prompt (zmiana PS1)
- Dodanie systemu Linux do domeny AD poprzez RealmD
- Instalacja ODBC MSSQL na dystrybucjach RHEL
- Przykładowe konfiguracje ODBC dla różnych baz danych
- Message of the day - MOTD
Podstawowe komendy użytkowe
Poruszanie się w CLI / BASH / SSH
Wprowadzenie:
W systemach Linux/Unix praca odbywa się głównie w środowisku tekstowym (terminalu). Zrozumienie, jak nawigować po systemie plików, jest fundamentem pracy administracyjnej. Poniżej przedstawiamy podstawowe i zaawansowane komendy do poruszania się po strukturze katalogów.
1. Komenda pwd – gdzie jestem?
pwdPolecenie pwd (print working directory) wyświetla pełną, bezwzględną ścieżkę do katalogu, w którym aktualnie się znajdujemy. Jest to podstawowa komenda pozwalająca na orientację w strukturze katalogów systemu.
Przykład:
$ pwd
/home/admin/projekty2. Komenda ls – co jest w katalogu?
lsKomenda ls (list) wyświetla listę plików i katalogów w bieżącym katalogu. To podstawowe narzędzie do przeglądania zawartości systemu plików.
Najczęściej używane opcje:
ls -lWyświetla szczegółowe informacje o plikach: uprawnienia, właściciela, grupę, rozmiar, datę modyfikacji i nazwę.
ls -aPokazuje również pliki ukryte (których nazwa zaczyna się od kropki .).
ls -lhŁączy opcję -l z -h (human-readable), wyświetlając rozmiary plików w formacie czytelnym dla człowieka (KB, MB, GB).
ls -lahPołączenie wszystkich trzech opcji – szczegółowy widok ze wszystkimi plikami (w tym ukrytymi) i czytelnymi rozmiarami.
ls -ltSortuje pliki według daty modyfikacji (najnowsze na górze).
ls -lSSortuje pliki według rozmiaru (największe na górze).
3. Komenda cd – poruszanie się między katalogami
cd /ścieżka/do/kataloguPolecenie cd (change directory) zmienia aktualny katalog roboczy na wskazany.
Najważniejsze sposoby użycia:
cd ~Przechodzi do katalogu domowego aktualnego użytkownika (np. /home/admin).
cd ..Przechodzi do katalogu nadrzędnego (rodzica) względem bieżącego katalogu.
cd -Wraca do poprzedniego katalogu, w którym byliśmy przed ostatnią zmianą.
cd ./katalogWchodzi do podkatalogu katalog znajdującego się w bieżącej lokalizacji.
cd /Przechodzi do katalogu głównego systemu (root directory).
4. Zrozumienie kropek w ścieżkach
.– oznacza bieżący katalog..– oznacza katalog nadrzędny (jeden poziom wyżej)~– oznacza katalog domowy użytkownika
Przykłady:
cd ../dokumenty # przejdź poziom wyżej, potem do katalogu dokumenty
cd ~/projekty # przejdź do katalogu projekty w katalogu domowym
cd ../../tmp # dwa poziomy wyżej, potem do katalogu tmp5. Komenda readlink – rozwijanie ścieżek
readlink -f nazwa_plikuPolecenie readlink z opcją -f wyświetla pełną, absolutną ścieżkę do pliku lub katalogu, rozwijając wszystkie linki symboliczne. Przydatne, gdy pracujemy z skrótami i chcemy poznać rzeczywistą lokalizację pliku.
6. Komenda tree – drzewo katalogów
treeWyświetla strukturę katalogów w formie drzewa (jeśli narzędzie jest zainstalowane). Pozwala na szybką wizualizację zagnieżdżenia katalogów.
tree -L 2Ogranicza głębokość wyświetlania do 2 poziomów.
Podsumowanie praktyczne:
# Sprawdź, gdzie jesteś
pwd
# Wyświetl pliki w bieżącym katalogu ze szczegółami
ls -lah
# Przejdź do katalogu projekty
cd ~/projekty
# Wróć do poprzedniego katalogu
cd -
# Przejdź poziom wyżej
cd ..
# Wyświetl pełną ścieżkę do pliku
readlink -f config.conf
Obsługa przegladania plików : CAT, HEAD, TAIL
1. cat – wyświetlanie zawartości pliku
cat plik.txtWyświetla całą zawartość pliku plik.txt na standardowe wyjście (terminal). Używany też do łączenia plików i przekierowania ich zawartości.
Przykład łączenia plików i zapisu do nowego pliku:
cat plik1.txt plik2.txt > polaczony_plik.txt2. head – wyświetlanie początkowych linii pliku
head plik.txtWyświetla domyślnie pierwsze 10 linii pliku plik.txt.
Zmiana liczby wyświetlanych linii:
head -n 20 plik.txtWyświetla pierwsze 20 linii pliku.
3. tail – wyświetlanie końcowych linii pliku
tail plik.txtWyświetla ostatnie 10 linii pliku.
Śledzenie zmieniającego się pliku (np. pliku logu):
tail -f /var/log/syslogNa żywo wyświetla kolejne dodawane linie do pliku (przydatne przy monitorowaniu logów).
Wyświetlenie określonej liczby ostatnich linii:
tail -n 50 plik.logOstatnie 50 linii pliku plik.log.
Praktyczne zastosowania połączeń narzędzi
Wyświetlenie ostatnich 100 linii z monitorowaniem na żywo (analogicznie jak tail -f):
tail -n 100 -f /var/log/system.logWyświetlenie pierwszych 50 linii wyszukanego pliku, np. połączone z grep:
grep "error" /var/log/syslog | head -n 50Parametry komendy ich wykorzystanie:
-n (–lines=ILE)Opcja pozwala określić liczbę wyświetlanych linii od końca pliku.
tail -n 20 plik.txtWyświetli ostatnie 20 linii pliku plik.txt. Domyślnie jest to 10 linii, jeśli nie podamy opcji.
-f (–follow[=OPTION])
Opcja stosowana do śledzenia pliku na bieżąco. Wypisuje najpierw ostatnie linie, potem wyświetla na żywo nowe linie dopisywane do pliku.
tail -f /var/log/syslogPrzydatne do monitorowania plików logów w czasie rzeczywistym.
-c (–bytes=ILE)
Wypisuje z pliku zamiast linii określoną liczbę ostatnich bajtów.
tail -c 100 plik.txtWyświetla ostatnie 100 bajtów pliku. Jeden bajt to jeden znak lub nowa linia.
-q (–quiet, –silent)
Przy wyświetlaniu wielu plików nie wyświetla ich nazw nad zawartością.
tail -q -n 10 plik1.txt plik2.txt-v (–verbose)
Zawsze wyświetla nazwę pliku nad jego zawartością nawet przy jednym pliku.
Inne przydatne opcje
--retry– wielokrotna próba otwarcia pliku, przydatne w monitorowaniu.--pid=PID– automatyczne zatrzymanie działania gdy zakończy się proces o podanym PID.-s N– opóźnienie między odczytami gdy używamy-f, domyślnie 1 sekunda.
Przykład kompleksowy:
tail -n 50 -f -s 2 /var/log/app.logWyświetla ostatnie 50 linii pliku app.log, a następnie śledzi plik, odświeżając co 2 sekundy.
Użycie w potoku i z filtrowaniem:
tail -f /var/log/app.log | grep --color "ERROR"Monitoruje na żywo plik logów i podświetla słowo "ERROR".
Obsługa komendy "ps" - Proces Status
Komenda ps (process status) jest jednym z fundamentalnych narzędzi administracyjnych do monitorowania procesów w systemach Unix/Linux. Pozwala na identyfikację, śledzenie i diagnostykę działających aplikacji. W pracy z serwerami (szczególnie przy Proxmox, FreeBSD czy administracji gra serwerów MT2) niezbędna jest umiejętność interpretacji wyniku ps.
Podstawowe użycie ps
psWyświetla procesy bieżącego użytkownika w aktualnej sesji terminalowej. Bardzo podstawowe, rzadko wystarczające dla administratora.
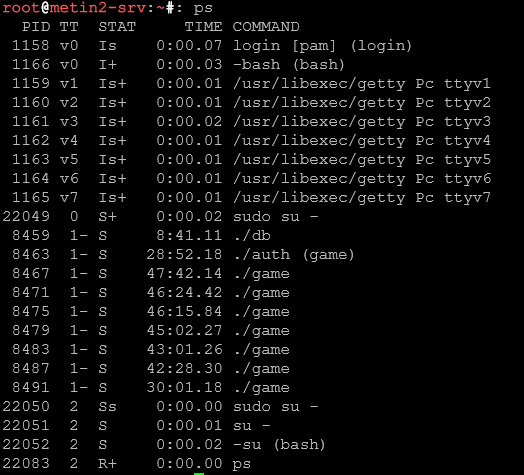
Przeglądanie wszystkich procesów z pełnymi informacjami
ps auxTo najczęstsze polecenie dla administratorów. Wyświetla wszystkie procesy w systemie (a – wszystkie, u – szczegółowy format, x – procesy bez terminala). Kolumny oznaczają: USER (właściciel), PID (ID procesu), %CPU (procent CPU), %MEM (procent pamięci), VSZ (rozmiar wirtualny), RSS (resident set size – fizyczna pamięć), TTY (terminal), STAT (status), START (czas startu), TIME (czas CPU), COMMAND (polecenie).
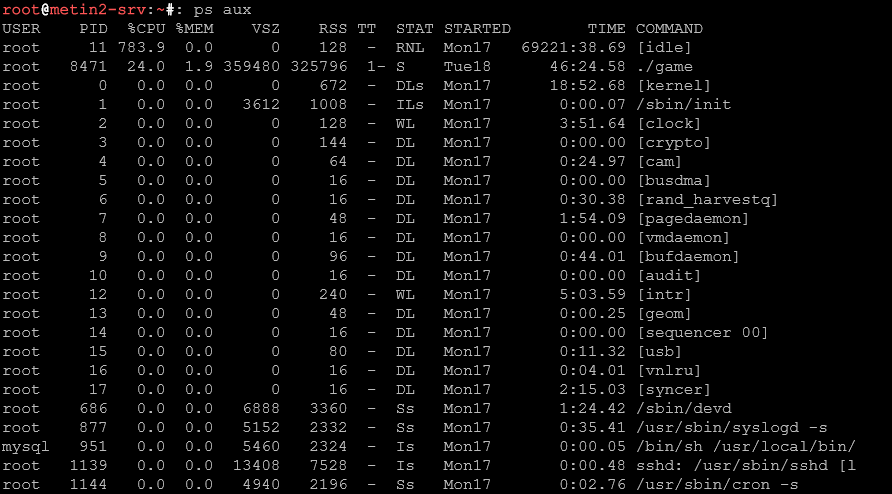
Alternatywny format wyświetlania
ps -efInny sposób na wyświetlenie wszystkich procesów, bardziej zbliżony do formatu Linuksa (zamiast BSD-owego aux). PPID (ID procesu nadrzędnego) jest tu bardziej widoczne.
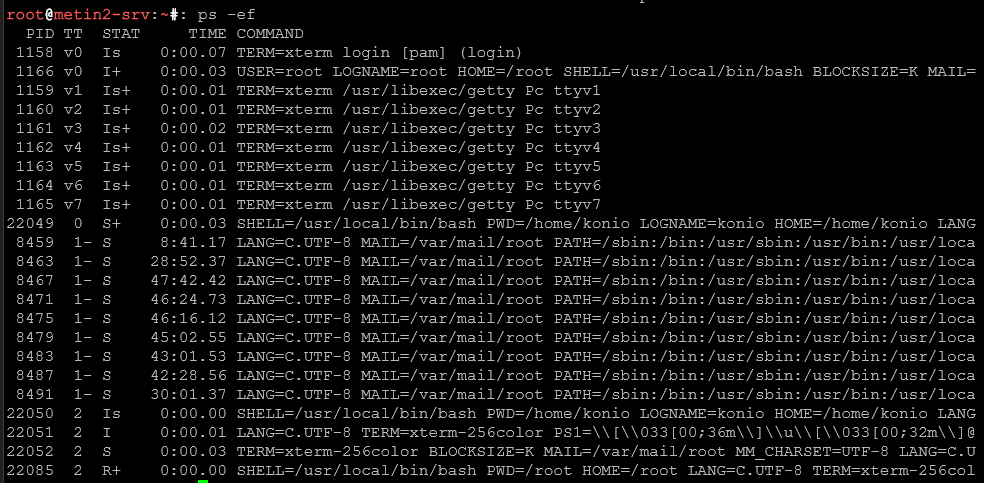
Filtrowanie procesów konkretnego użytkownika
ps -u 'nazwa_usera'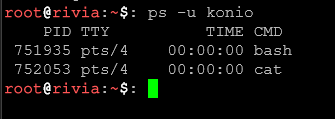
Pokazuje tylko procesy należące do użytkownika admin. Przydatne gdy szukamy co robi konkretny użytkownik.
ps -u root,www-dataProcesy należące do wielu użytkowników naraz.
Wyszukiwanie konkretnych procesów
ps aux | grep 'nazwa procesu'Wyszukuje procesy związane z danym procesem
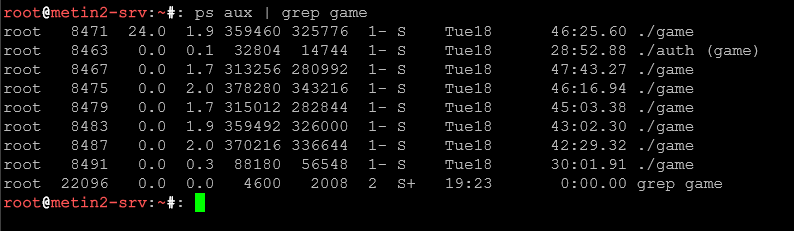
ps aux | grep -v grep |
 |
Eliminuje z wyniku samo polecenie grep (często pojawia się w wynikach).
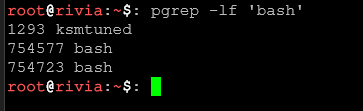
pgrep -lf 'nazwa_procesu'Szuka procesu po pełnej nazwie polecenia (bardziej precyzyjne niż grep).
Sortowanie procesów
ps aux --sort=-%cpu | head -20Wyświetla 20 procesów zużywających najwięcej CPU, posortowanych malejąco.
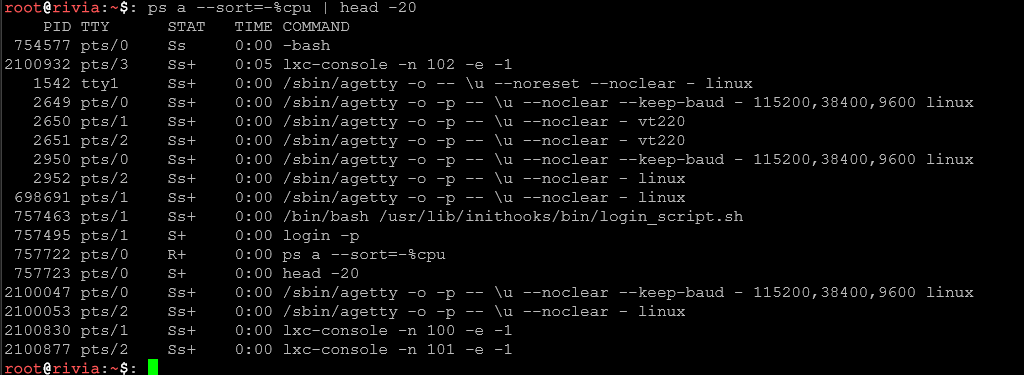
ps aux --sort=-%mem | head -20Wyświetla 20 procesów zużywających najwięcej pamięci RAM.
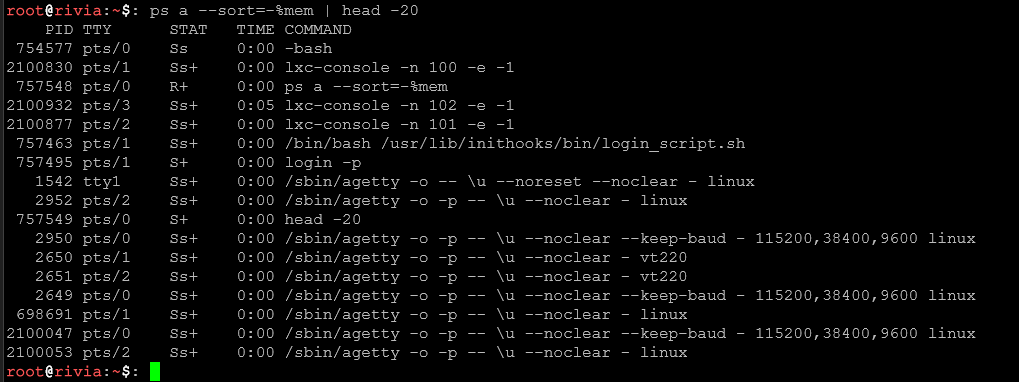
ps aux --sort=-vszSortuje po wirtualnym rozmiarze pamięci.
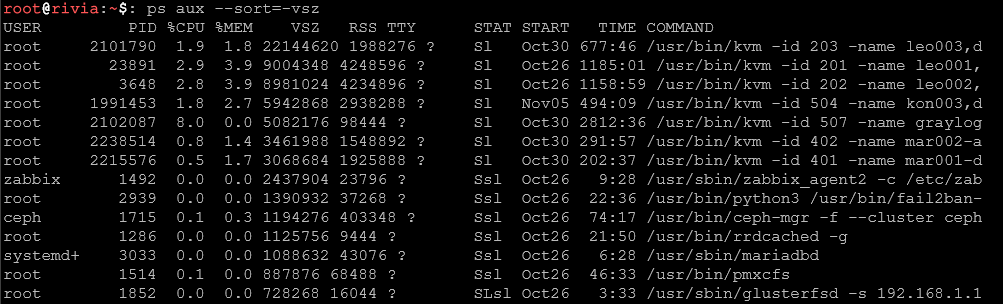
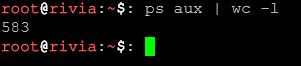
ps aux | wc -lLiczy całkowitą liczbę procesów w systemie.
Monitorowanie procesów hiearchy – relacje między procesami
ps auxfWyświetla procesy w formie drzewa, pokazując które procesy są "dziećmi" innych procesów.
pstree -p userPokazuje drzewo procesów danego użytkownika z PID.
Monitorowanie procesów w czasie – status i sygnały
ps aux | grep -E 'S|Ss|R|T'Statusy procesów: S (sleeping – uśpiony), Ss (session leader), R (running – działający), T (stopped – zatrzymany), Z (zombie).
Zombie procesy – problem w naszych czatach:
ps aux | grep ZWyszukuje procesy zombie (znane z naszych dzienników z serwera MT2SRV, gdzie czasami pojawiały się procesy nieusunięte prawidłowo).
Wyświetlanie konkretnych kolumn
ps -o pid,user,%cpu,%mem,commWyświetla tylko wybrane kolumny: PID, użytkownik, CPU, pamięć i nazwa polecenia.
ps aux -o pid,ppid,user,commPID, PPID (proces nadrzędny), użytkownik i nazwa polecenia – przydatne do zrozumienia zależności między procesami.
Monitorowanie procesów w pętli rzeczywistej – ale nie programem top
while true; do ps aux | grep game; sleep 2; doneMonitoruje konkretny proces co 2 sekundy. Przydatne gdy chcemy obserwować czy proces się restartuje.
Specjalistyczne zapytania
ps aux | awk '$3 > 10 { print $0 }'Wyświetla procesy zużywające więcej niż 10% CPU.
ps aux | awk '$4 > 20 { print $2, $4, $11 }'Wyświetla procesy zużywające więcej niż 20% pamięci (PID, %MEM, komenda).
Praktyczne scenariusze
# Sprawdzenie stanu serwera gry MT2SRV
ps aux | grep -E 'game|db|auth'Szukamy trzech kluczowych procesów serwera.
# Znalezienie procesu zużywającego zasoby
ps aux --sort=-%mem | head -1Proces zużywający największą pamięci.
# Znalezienie i zabicie zombie procesów
ps aux | grep Z | awk '{print $2}' | xargs kill -9Ostrożnie! Usuwa procesy zombie (choć powinny być usunięte automatycznie).
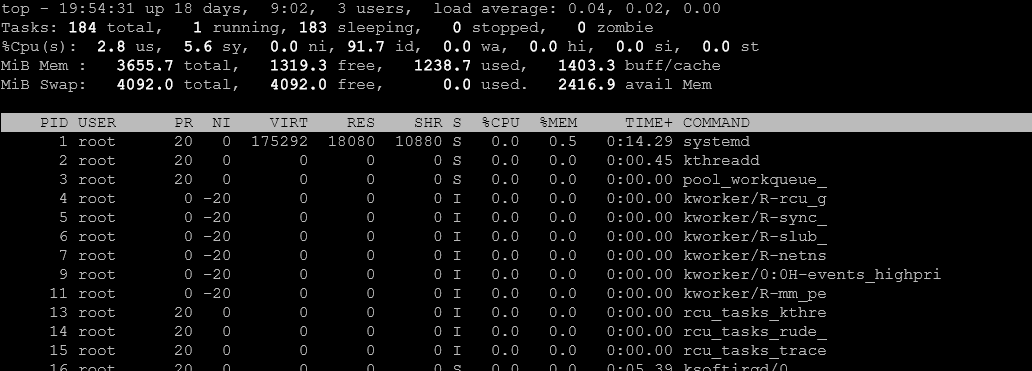
Monitorowanie procesów na żywo: top i htop
top to standardowe narzędzie do monitorowania systemu w czasie rzeczywistym. htop to nowoczesna, bardziej przyjazna alternatywa z kolorowym interfejsem i lepszą nawigacją.
Komenda top – klasyczne monitorowanie
topUruchamia interaktywny monitor systemowy. Domyślnie sortuje procesy wg CPU.
Klawisze i komendy w top
q – wyjście z top
h – pomoc
M – sortuj wg pamięci (zamiast CPU)
P – sortuj wg CPU (domyślnie)
T – sortuj wg czasu uruchomienia
u – pokaż procesy konkretnego użytkownika
k – zabij proces (przydatne gdy proces "szaleje")
r – zmień priorytet procesu (nice value)
Uruchamianie top z opcjami
top -u 'nazwa_usera'Pokazuje tylko procesy użytkownika admin.
top -p 1234,5678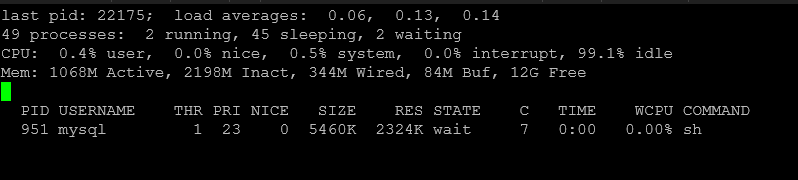
Monitoruje konkretne procesy po PID.
top -n 1Pokazuje tylko jeden snapshot (raz odświeża) i wyłącza się (przydatne w skryptach).
top -o %MEMSortuj wg zużycia pamięci przy uruchomieniu.
Praktyczne zastosowanie z naszych czatów:
top -p $(pgrep -f game | tr '\n' ','))Monitoruj procesy serwera gry (game, db, auth).
Komenda htop – ulepszona wersja
htopUruchamia interaktywny monitor z kolorowym interfejsem.
Zalety htop nad top
- Kolorowy, bardziej czytelny interfejs
- Możliwość zaznaczania wielu procesów naraz
- Łatwiejsze filtrowanie i wyszukiwanie
- Łatwiejsze zabijanie procesów bez znajomości ich PID
- Drzewo procesów (Forest View)
Klawisze w htop
q – wyjście
F3 – wyszukaj proces
F4 – filtruj (np. po użytkowniku)
F5 – widok drzewa procesów
F6 – zmień kolumnę sortowania
F9 – wyślij sygnał do procesu (kill, SIGSTOP, etc.)
u – pokaż procesy użytkownika
Porównanie top vs htop
| Cecha | top |
htop |
|---|---|---|
| Dostępność | Zawsze zainstalowany | Wymaga instalacji |
| Interfejs | Tekstowy | Kolorowy, przyjazny |
| Wyszukiwanie | Trudne | Łatwe (F3) |
| Zabijanie procesów | Wymaga PID | Zaznacz i F9 |
| Drzewo procesów | Brak | F5 |
Wykorzystanie htop
htop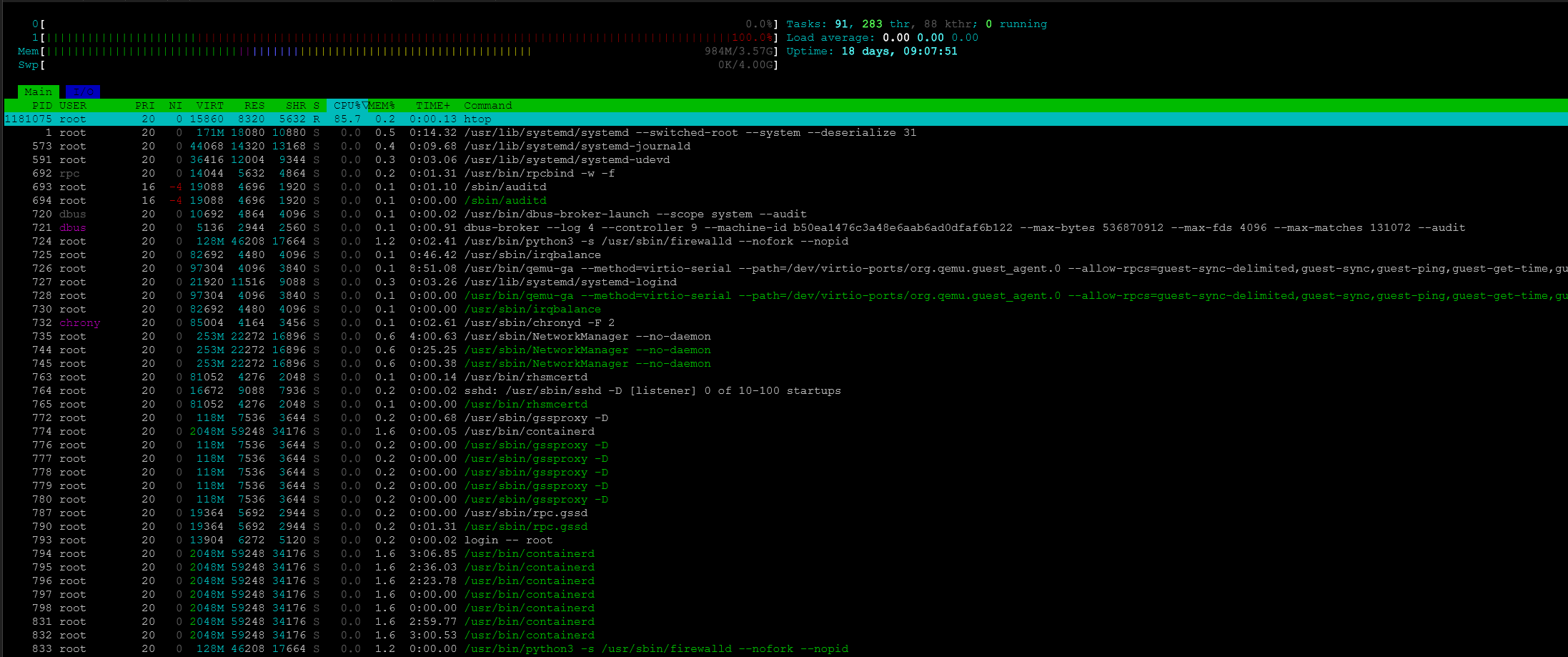
Uruchom htop, press F4 by filtrować procesy, wpisz np "docker".
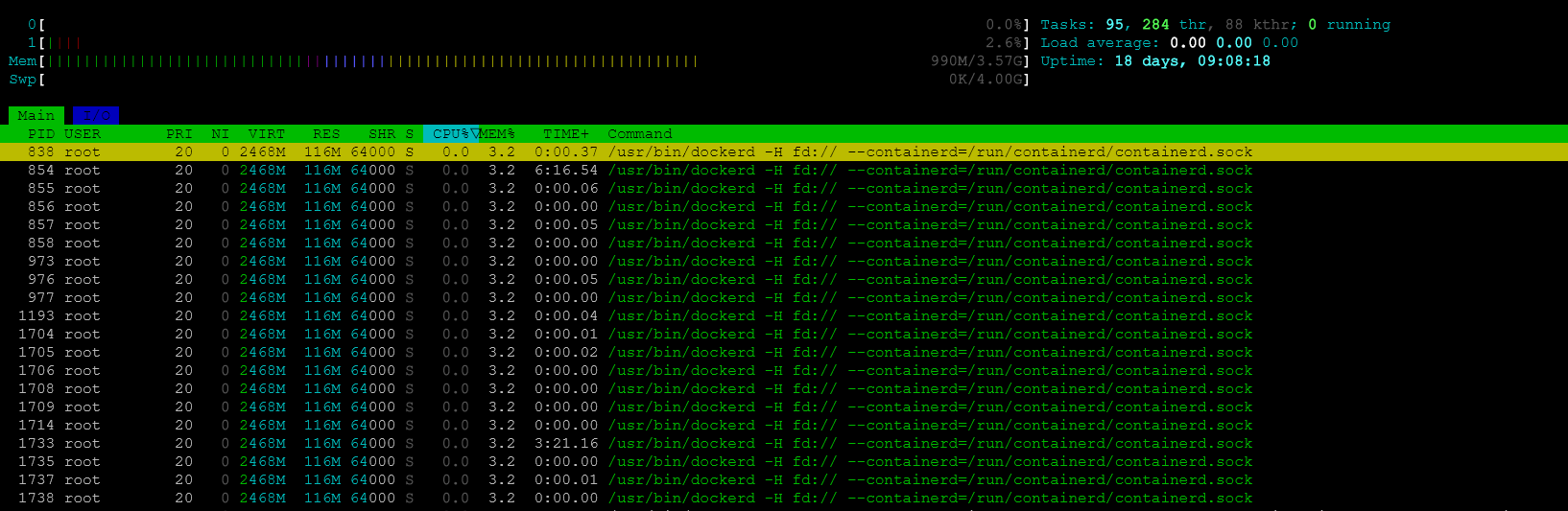
Zabij proces szalejący (zużywający 100% CPU):
topZnajdź proces, naciśnij k, wpisz sygnał (9 dla SIGKILL).
Monitoruj konkretny proces i jego dzieci (fork):
htop -p [PID]Lub w htop: F5 dla Forest View, wyszukaj proces.
Zaawansowane wyszukiwanie z użyciem find i grep
1. find – wyszukiwanie plików i katalogów
find /ścieżka -iname "wzorzec"Szukamy plików lub katalogów według nazwy ze zignorowaniem wielkości liter (opcja -iname).
Przykład: find /var/log -iname "*.LOG" znajdzie wszystkie pliki z rozszerzeniem .log lub .LOG.
find . -type fSzukamy wyłącznie zwykłych plików w bieżącym katalogu i jego podkatalogach. (-type f = file)
find . -type dSzukamy tylko katalogów. (-type d = directory)
find /home -mtime -7Wyszukujemy pliki zmodyfikowane w ciągu ostatnich 7 dni. (-mtime to czas modyfikacji, -7 oznacza mniej niż 7 dni temu)
find /var/www -size +10MWyszukujemy pliki większe niż 10 megabajtów. (+10M oznacza większe niż 10MB)
Co oznaczają opcje:
-iname– wyszukiwanie nazwy pliku bez zwracania uwagi na wielkość liter.-name– wyszukiwanie nazwy pliku uwzględnia wielkość liter.-type f/d/l– filtr według typu: f = plik zwykły, d = katalog, l = link symboliczny.-mtime N– pliki modyfikowane dokładnie N dni temu;-mtime -N– zmodyfikowane w ciągu ostatnich N dni.-size +N– pliki większe niż N jednostek (k, M, G).
2. grep – wyszukiwanie tekstu wewnątrz plików lub strumieni danych
grep "wzorzec" plik.txtWyszukuje linie zawierające wzorzec w podanym pliku.
grep -i "blad" plik.txtIgnoruje wielkość liter, znajdzie "blad", "Blad", "BLAD" itd.
grep -r "error" /var/logRekurencyjnie wyszukuje słowo "error" we wszystkich plikach w katalogu /var/log.
grep -n "start" plik.txtWyświetla numer linii, w której znaleziono dopasowanie.
grep -c "fail" plik.txtLiczy liczbę linii, które zawierają "fail".
grep -v "warning" plik.txtWyświetla linie, które nie zawierają słowa "warning".
grep -l "TODO" *.cWyświetla tylko nazwy plików z rozszerzeniem .c, w których znaleziono słowo "TODO".
Opisy opcji:
-i– ignoruj wielkość liter;-r– rekurencyjne przeszukiwanie katalogów;-n– pokazywanie numerów linii;-c– liczenie wystąpień;-v– negacja wzorca (linia nie zawiera wzorca);-l– pokazuje tylko nazwy plików z dopasowaniem.
3. Łączenie find z grep – wyszukiwanie wzorców tekstowych w określonych plikach
find /var/www -type f -name "*.php" -exec grep -l "mysqli_connect" {} \;Znajduje wszystkie pliki .php w katalogu /var/www, które zawierają tekst "mysqli_connect".
find /var/www -type f -iname "*.conf" -exec grep -iH "server" {} \;Znajduje pliki konfiguracyjne (bez zwracania uwagi na wielkość liter w nazwie) zawierające słowo "server" (ignorując wielkość liter, pokazując nazwy plików i linie).
find . -iname "test*" -print0 | xargs -0 grep -l "error"Wyszukuje pliki zaczynające się na "test" i sprawdza, czy zawierają słowo "error". Bezpieczne dla nazw z odstępami dzięki -print0 i xargs -0.
Praktyczne wskazówki
- Używaj
-inamew find, jeśli nie jesteś pewien wielkości liter w nazwach plików. - Łącz
findzgrepprzy pomocy-execlubxargs, aby wyszukiwać w treści plików wybrane wzorce. - Opcje
grep-ri--includepozwalają filtrować rekurencyjne wyszukiwania wg typu plików. - Przetestuj zapytania na mniejszych katalogach dla sprawdzenia wyników przed uruchomieniem na dużych strukturach.
Podsumowanie
find i grep to podstawowe, lecz bardzo potężne narzędzia do wyszukiwania plików i danych w nich zawartych, ich właściwe stosowanie znacząco ułatwia administrowanie systemami i skryptowanie operacji.
Obsługa dysków i systemów plików: df, du, lsblk, lscsi
Zarządzanie dyskami i miejscem na nich to kluczowa część administracji systemów. W serwerach (szczególnie Proxmox, FreeBSD czy serwery gier) ważne jest monitorowanie pojemności dysków i szybkie diagnozowanie problemów z miejscem na dysku. Gdy dysk się zapełni, serwis przestaje działać – stąd konieczność bieżącego monitorowania i konserwacji.
Komenda df – informacje o systemach plików
dfWyświetla użycie dysku dla wszystkich zamontowanych systemów plików (domyślnie w blokach 1K). Jest to podstawowe narzędzie do szybkiego sprawdzenia "ile miejsca zostało".

df -hFormat czytelny (B, KB, MB, GB) – najczęstszy sposób użycia. Zamiast liczb takich jak 15360000 zobaczymy 15G.
df -HFormat dziesiętny (1000 zamiast 1024 jako podstawa) – dla jednostek SI. Niektórzy wolą taki zapis.
df -TDodaje kolumnę z typem systemu plików (ext4, xfs, btrfs, zfs, ntfs, etc.). Przydatne gdy zarządzasz różnymi typami systemów plików.
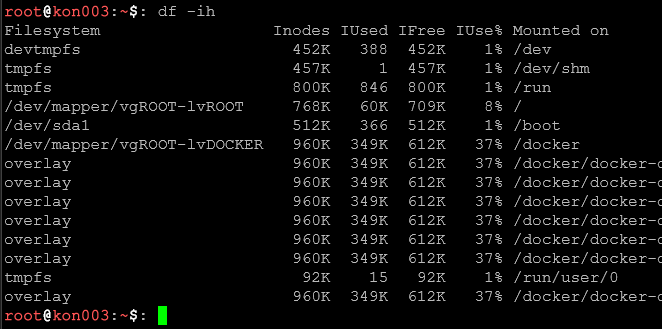
df -iWyświetla inode'y zamiast bloków. Ważne: można mieć wolne miejsce, ale brak inode'ów (gdy mamy miliony małych plików). System wtedy nie pozwoli tworzyć nowych plików mimo wolnego miejsca!
Praktyczne kombinacje:
df -ThTyp systemu plików i format czytelny – najbardziej praktyczna forma dla administratorów.
df -h | grep -v tmpfsUkryj tymczasowe systemy plików tmpfs, devtmpfs (często nieistotne).
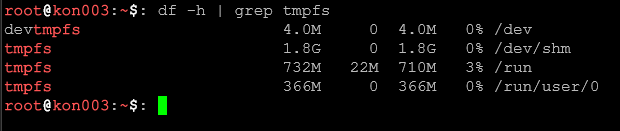
df -h | awk '$5 > 80 {print $0}'Pokaż tylko dyski zapełnione powyżej 80% (kolumna 5 to procent użycia).
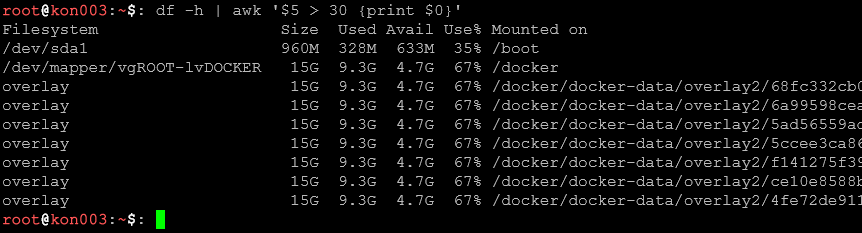
df -hT | sort -k6 -rnPosortuj dyski wg procentu zajęcia miejsca (kolumna 6) malejąco – szybko znajdziesz problematyczne dyski.
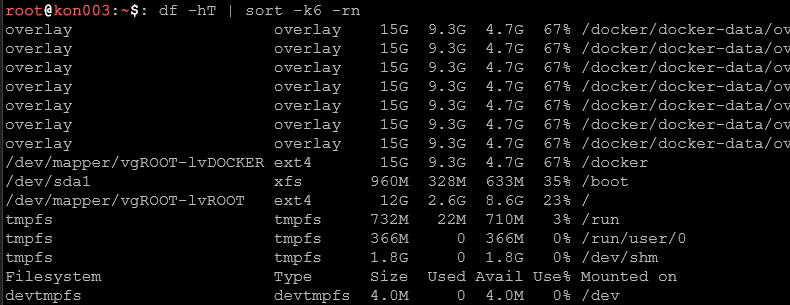
Komenda du – rozmiar katalogów i plików
du (disk usage) pokazuje ile miejsca zajmują poszczególne katalogi i pliki. Jest niezbędne gdy df pokazuje że dysk jest pełny, a potrzebujemy znaleźć które katalogi lub pliki odpowiadają za ten stan.
du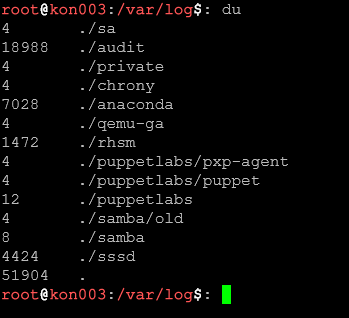
Domyślnie wyświetla rozmiary wszystkich podkatalogów rekurencyjnie (może wypisać tysiące linii!).
du -hFormat czytelny (KB, MB, GB).
du -sh katalog/Podsumowanie (-s, summary) rozmiaru katalogu w czytelnym formacie.
Wszystkie pliki i katalogi (-a, all) z rozmiarami – pokaże też pojedyncze pliki, nie tylko katalogi.
du -d 1 -h /varOgraniczenie głębokości (-d 1) do jednego poziomu – nie wchodzi głębiej w strukturę.
Znalezienie największych katalogów i plików:
du -ah /var | sort -rh | head -2020 największych plików i podkatalogów w /var (sortuj malejąco wg rozmiaru czytelnego dla człowieka).
du -sh /* 2>/dev/null | sort -rhSprawdź rozmiar wszystkich głównych katalogów systemu (/, /home, /var, /usr itd), ignoruj błędy dostępu.
find /var -type f -size +100M -exec ls -lh {} \; | awk '{print $5, $9}' | sort -rh
Znajdź wszystkie pliki większe niż 100MB. Przydatne gdy szukasz co zabiera miejsce.
find /var/log -type f -size +1GZnajdź pliki logów większe niż 1GB – często to one zapełniają dysk.

Praktyczne scenariusze z doświadczeń sysadmina:
# Dysk pełny na serwerze – diagnoza krok po kroku
df -h # Sprawdź który dysk jest pełny
du -sh /* | sort -rh # Szukaj dużych katalogów głównych
du -sh /var/* | sort -rh # Zagłębienie w /var
du -sh /var/log/* | sort -rh # Sprawdź logiSprawdź rozmiar bazy danych
du -sh /var/lib/mysql
du -sh /var/lib/postgresqlSprawdź cache, tymczasowe pliki
du -sh /tmp /var/tmp /var/cacheKomenda lsblk – lista urządzeń blokowych
Wprowadzenie:
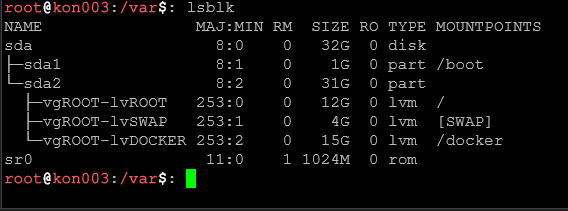
lsblk wyświetla strukturę dysków twardych, partycji, wolumenów logicznych (LVM) oraz punktów montowania. Niezastąpione gdy chcesz szybko zobaczyć "co jest podpięte i gdzie".
lsblkWyświetla wszystkie urządzenia blokowe w formie drzewa. Idealnie pokazuje relacje między dyskami, partycjami i punktami montowania.
lsblk -fDodatkowo pokazuje systemy plików, UUID, etykiety (labels) i procent użycia.

lsblk -o NAME,SIZE,TYPE,MOUNTPOINT,FSTYPEWybrane kolumny – dostosuj wyświetlanie do swoich potrzeb.
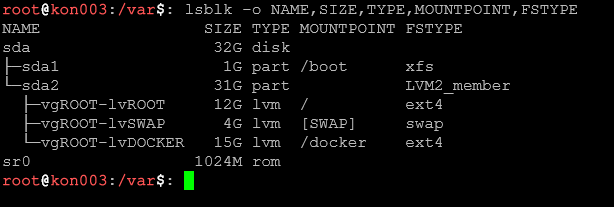
lsblk -pPokazuje pełne ścieżki urządzeń (np. /dev/sda zamiast sda).
Komenda lscsi – lista urządzeń SCSI/SATA
lscsiWyświetla listę podłączonych urządzeń SCSI/SATA. Przydatne do weryfikacji że wszystkie dyski fizyczne są widoczne w systemie.

lscsi -sDodaje rozmiar dysków.

Monitorowanie I/O dysku w czasie rzeczywistym
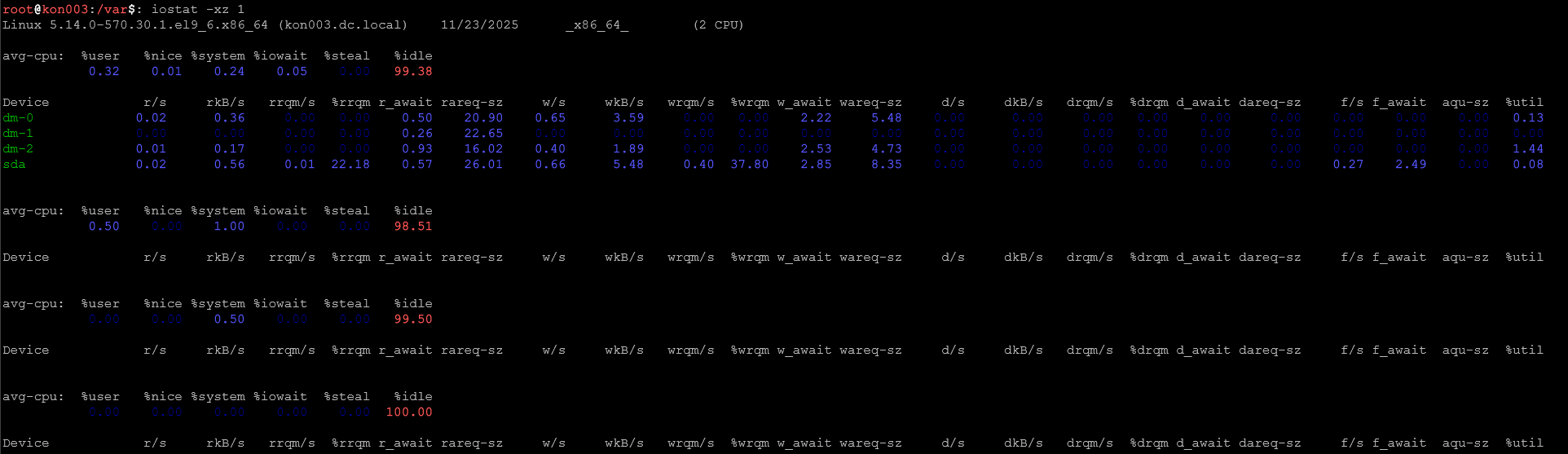
iostat -xz 1Monitoruj operacje I/O na dyskach co sekundę (wymaga pakietu sysstat). Szukaj kolumny %util > 80% – oznacza mocne obciążenie dysku.
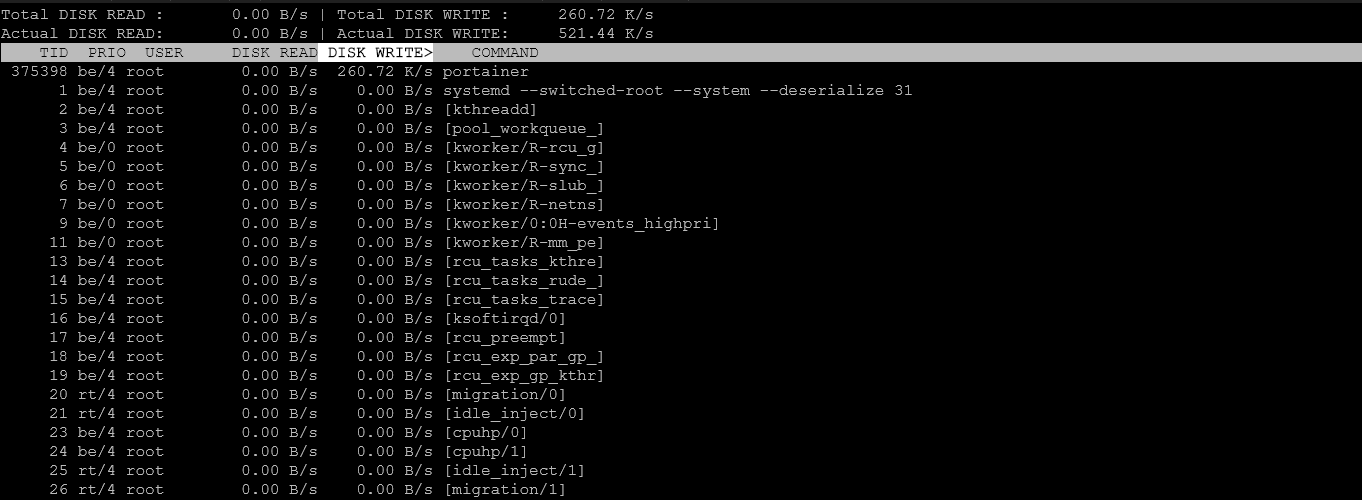
iotopInteraktywne narzędzie pokazujące które procesy generują najwięcej operacji I/O (wymaga instalacji i uprawnień root).
watch -n 1 'df -h | grep -v tmpfs'Monitoruj zmiany w zajęciu dysku co sekundę (przydatne gdy coś szybko zabiera miejsce).
Diagnostyka problemów z dyskiem – praktyczne scenariusze
Problem: Dysk nagle zapełniony
# Krok 1: Sprawdź który system plików
df -h
# Krok 2: Szukaj dużych katalogów (zacznij od głównych)
du -sh /* 2>/dev/null | sort -rh | head -10
# Krok 3: Zagłębienie (np. jeśli /var jest duży)
du -sh /var/* | sort -rh | head -10
# Krok 4: Sprawdź logi
du -sh /var/log/*
find /var/log -type f -size +500M -exec ls -lh {} \;
# Krok 5: Sprawdź czy nie ma usuniętych plików nadal otwartych
lsof +L1 | grep deletedProblem: Brak miejsca mimo że pliki nie zajmują tyle
# Sprawdź inode'y (mogą się skończyć przy wielu małych plikach)
df -i
# Jeśli inode'y na wyczerpaniu, znajdź katalogi z wieloma plikami
find / -xdev -printf '%h\n' | sort | uniq -c | sort -rn | head -20Problem: Serwer gry MT2SRV – logi zapełniają dysk
# Sprawdź rozmiar logów gry
du -sh /path/to/game/log/*
# Usuń stare logi (ostrożnie!)
find /path/to/game/log -name "*.log" -mtime +7 -delete
# Skompresuj duże logi zamiast usuwać
find /path/to/game/log -name "*.log" -size +100M -exec gzip {} \;Czyszczenie dysku – bezpieczne metody:
# Wyczyść cache pakietów (Debian/Ubuntu)
apt clean
apt autoclean
# Wyczyść cache pakietów (RedHat/CentOS)
yum clean all
# Usuń stare kernele (Ubuntu - ostożnie!)
apt autoremove --purge
# Wyczyść dzienniki systemd starsze niż 7 dni
journalctl --vacuum-time=7d
# Wyczyść pliki tymczasowe starsze niż 10 dni
find /tmp -type f -mtime +10 -deleteMonitorowanie trendu zajęcia dysku
# Zapisz snapshot dziennie
df -h > /var/log/disk_usage_$(date +%Y%m%d).txt
# Porównaj z wczoraj
diff /var/log/disk_usage_20251122.txt /var/log/disk_usage_20251123.txt# Prosty skrypt alertu gdy dysk > 90%
#!/bin/bash
USAGE=$(df -h / | awk 'NR==2 {print $5}' | tr -d '%')
if [ $USAGE -gt 90 ]; then
echo "ALERT: Dysk zapełniony w $USAGE%" | mail -s "Disk Alert" admin@example.com
fiSprawdzanie stanu zdrowia dysku (S.M.A.R.T.) (wymaga pakietu smartmontools).
smartctl -a /dev/sda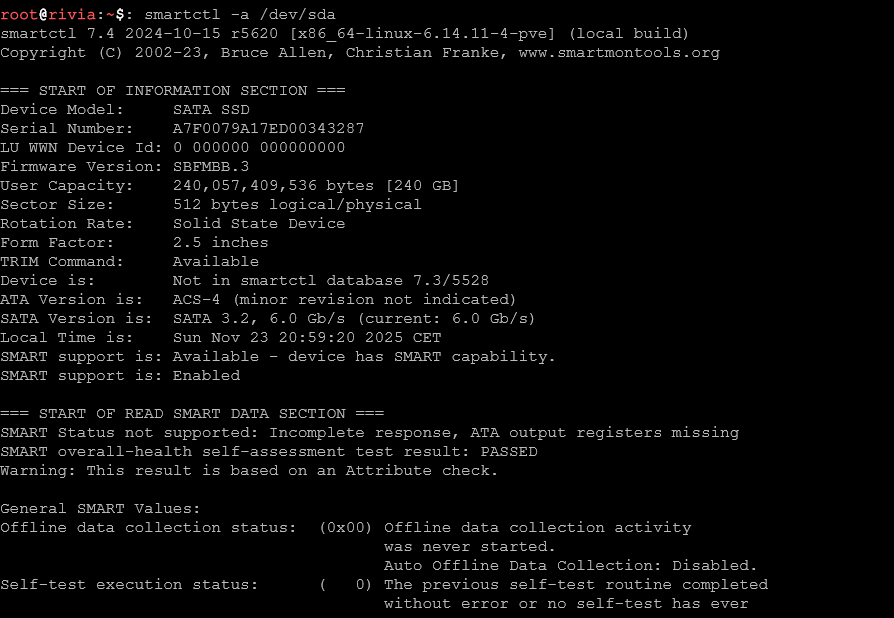
Wyświetla szczegółowe informacje o stanie dysku z S.M.A.R.T.
smartctl -H /dev/sda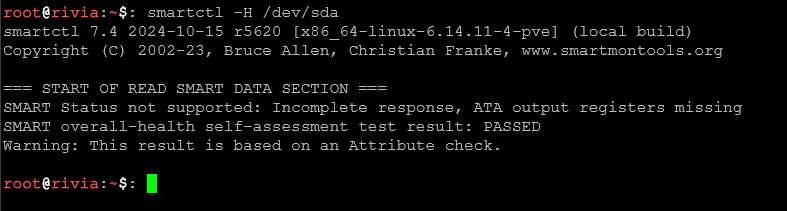
Szybki test zdrowia dysku (PASSED/FAILED).
LVM, RAID i ZFS
Dla systemów z LVM:
lvs # Lista logical volumes
pvs # Lista physical volumes
vgs # Lista volume groups
lvdisplay # Szczegóły LV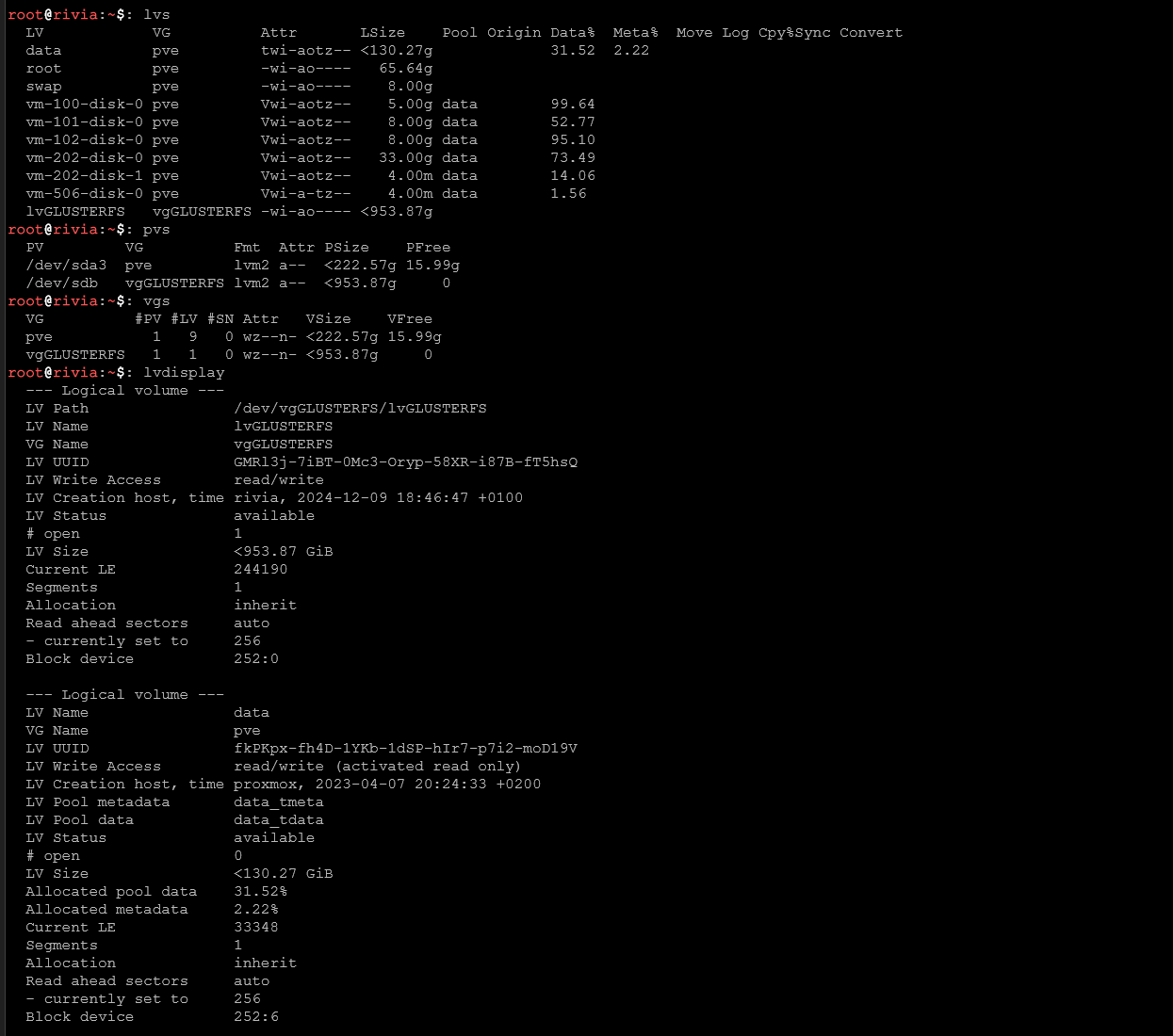
Dla systemów z RAID:
cat /proc/mdstat # Status software RAID
mdadm --detail /dev/md0 # Szczegóły RAID arrayDla systemów z ZFS (FreeBSD, Linux z ZFS):
zpool list # Lista pool'i ZFS
zpool status # Status pool'i
zfs list # Lista systemów plików ZFS
zfs get all # Wszystkie właściwościPodsumowanie praktycznych komend
# Quick check – co się dzieje z dyskami
df -Th
du -sh /* | sort -rh | head -10
lsblk -f
# Deep dive – znajdź największe pliki
find / -type f -size +1G -exec ls -lh {} \; 2>/dev/null
# Monitoring w czasie rzeczywistym
watch -n 2 'df -h; echo ""; du -sh /var/log /var/cache /tmp'
# Diagnoza performance
iostat -xz 2 5
iotop -o # tylko aktywne procesy I/O
Linki symboliczne i twarde w systemach Linux/Unix
Wprowadzenie:
Linki w systemach Linux pozwalają na tworzenie alternatywnych nazw i dróg dostępu do plików bez duplikowania ich zawartości. Są dwa typy linków: symboliczne (symlinki) i twarde (hard links), każdy z nich ma swoje zastosowania i ograniczenia.
1. Link symboliczny (symbolic link, symlink)
Co to jest link symboliczny?
Link symboliczny to specjalny plik, który zawiera ścieżkę do innego pliku lub katalogu. Można go traktować jak "skrót" w systemach Windows. Link wskazuje na lokalizację docelową, ale sam nie zawiera danych oryginalnego pliku.
Tworzenie linku symbolicznego:
ln -s /ścieżka/do/originalu /ścieżka/do/linkuPrzykłady praktyczne:
ln -s /usr/local/bin/python3.11 /usr/local/bin/pythonTworzy link python wskazujący na python3.11. Dzięki temu można wywoływać python zamiast pełnej nazwy.
ln -s /var/www/html/projekty/strona ~/strona_linkTworzy wygodny skrót do katalogu projektu w katalogu domowym.
ln -s /mnt/dysk_zewnetrzny/backup ~/backupSkrót do katalogu backupu na zewnętrznym dysku.
Sprawdzanie linków symbolicznych:
ls -l link_nazwaWyświetla informację o linku i pokazuje gdzie wskazuje, np.:
lrwxrwxrwx 1 user user 24 Nov 23 15:00 strona_link -> /var/www/html/projekty/stronaUsuwanie linku symbolicznego:
rm link_nazwaUwaga: usuwanie linku nie usuwa pliku docelowego!
Cechy linków symbolicznych:
- Mogą wskazywać na pliki i katalogi
- Mogą wskazywać na nieistniejące cele (tzw. "wiszące linki")
- Działają między różnymi systemami plików i partycjami
- Są widoczne jako osobny typ pliku (oznaczenie
lwls -l)
2. Link twardy (hard link)
Co to jest link twardy?
Link twardy to dodatkowa nazwa dla tego samego pliku na dysku. W przeciwieństwie do linku symbolicznego, link twardy wskazuje bezpośrednio na te same dane (ten sam inode) co oryginalny plik. W praktyce nie ma różnicy między "oryginałem" a "linkiem" – oba są równorzędnymi nazwami tego samego pliku.
Tworzenie linku twardego:
ln /ścieżka/do/pliku /ścieżka/do/twardego_linkuPrzykłady praktyczne:
ln /var/log/syslog /home/admin/syslog_backupTworzy drugi dostęp do tego samego pliku logów. Modyfikacja w jednym miejscu jest widoczna w drugim.
ln dokument.txt dokument_kopia.txtObie nazwy wskazują na ten sam plik. Usunięcie jednej nazwy nie usuwa danych, dopóki istnieje druga.
Sprawdzanie linków twardych:
ls -li plikOpcja -i pokazuje numer inode. Pliki o tym samym numerze inode to linki twarde do tych samych danych.
$ ls -li dokument.txt dokument_kopia.txt
12345678 -rw-r--r-- 2 user user 1024 Nov 23 15:00 dokument.txt
12345678 -rw-r--r-- 2 user user 1024 Nov 23 15:00 dokument_kopia.txtTen sam numer inode (12345678) i liczba linków "2" oznacza, że to linki twarde.
Cechy linków twardych:
- Działają tylko dla plików (nie dla katalogów)
- Muszą być w tym samym systemie plików
- Plik jest usuwany dopiero gdy usuniemy wszystkie linki twarde do niego
- Nie są widoczne jako osobny typ – wyglądają jak zwykłe pliki
3. Różnice między linkami symbolicznymi a twardymi
| Cecha | Link symboliczny | Link twardy |
|---|---|---|
| Typ | Wskaźnik do ścieżki | Dodatkowa nazwa pliku |
| Katalogi | Tak | Nie |
| Różne systemy plików | Tak | Nie |
| Po usunięciu oryginału | Link "wiszący" | Dane nadal dostępne |
4. Praktyczne zastosowania
# Link symboliczny do aktualnej wersji aplikacji
ln -s /opt/app-1.2.3 /opt/app
# Link symboliczny do konfiguracji
ln -s /etc/nginx/sites-available/strona.conf /etc/nginx/sites-enabled/strona.conf
# Link twardy jako backup przed edycją
ln ważny_plik.conf ważny_plik.conf.backup
# Sprawdzenie gdzie prowadzi link
readlink -f link_nazwa
# Znalezienie wszystkich linków twardych do pliku
find / -inum $(ls -i plik | awk '{print $1}') 2>/dev/null
Monitorowanie zasobów: free, vmstat, iostat, sara
Monitorowanie dostępnej pamięci jest kluczowe dla stabilności systemu. Przy administracji serwerami, maszyn wirtualnych czy serwerów ważne jest zrozumienie jak Linux alokuje i zarządza pamięcią.
Komenda free – stan pamięci teraz
free
Wyświetla podsumowanie zużycia RAM i swap. Domyślnie w kilobajtach (KB).
free -hFormat czytelny (B, KB, MB, GB). Najczęściej stosowana opcja.

free -m
Wynik w megabajtach.
free -g
Wynik w gigabajtach (przydatne na dużych serwerach).
free -wRozszerzony format z osobną kolumną na bufory i cache.

Interpretacja wyniku free -h:
total used free shared buff/cache available Mem: 15.6G 8.2G 2.1G 0.5G 5.3G 7.4G Swap: 4.0G 0.5G 3.5G
total– całkowita pamięć RAMused– faktycznie używana pamięćfree– zupełnie wolna (często mała, bo Linux używa cache)buff/cache– bufory i cache (mogą być zwolnione, jeśli trzeba)available– pamięć dostępna do użytku dla aplikacji (ważna liczba!)
Monitorowanie pamięci w czasie rzeczywistym
free -h -s 2Wyświetla stan pamięci co 2 sekundy.
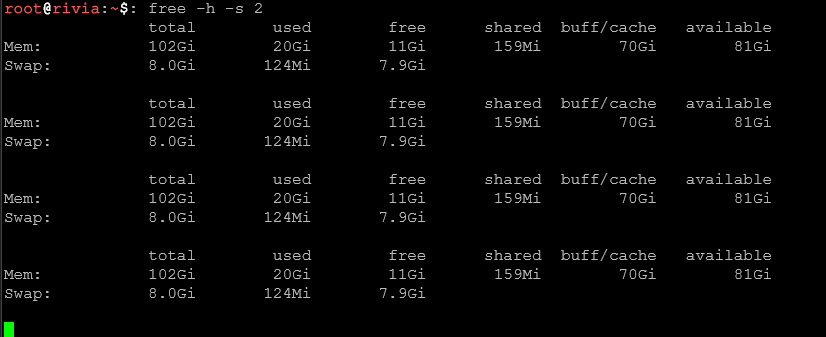
free -h -s 2 -c 10Monitoruje co 2 sekundy, 10 razy.
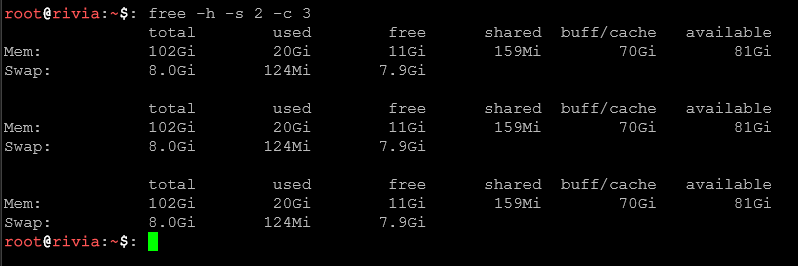
watch -n 1 'free -h'Monitorowanie pamięci co sekundę w atrakcyjnym formacie (wymaga pakietu watch).

Komenda vmstat – Virtual Memory Statistics
Wprowadzenie do vmstat:
Bardziej zaawansowana niż free, pokazuje statystyki pamięci wirtualnej, I/O i swap activity.
vmstat
Jednorazowy raport.
vmstat 2 5Raport co 2 sekundy, 5 razy.

Interpretacja wyniku:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 2048000 51200 5242880 0 0 2 1 50 30 25 5 70 0 0
r– procesy czekające na CPUb– procesy w I/O waitswpd– swap w użyciu (MB)free– wolna pamięćsi/so– swap in/out (jeśli > 0, system ma problemy z pamięcią)id– % czasu CPU bezczynny (wysoki = dobry, niski = CPU obciążony)wa– % czasu czekania na I/O (wysokie wartości = problemy z dyskiem)
Komenda iostat – I/O Statistics
iostat monitoruje aktywność dysków i procesorów. Wymaga pakietu sysstat.
iostatOgólne statystyki od ostatniego restartu systemu.

iostat -x 2 5Rozszerzone statystyki dysku, co 2 sekundy, 5 razy.
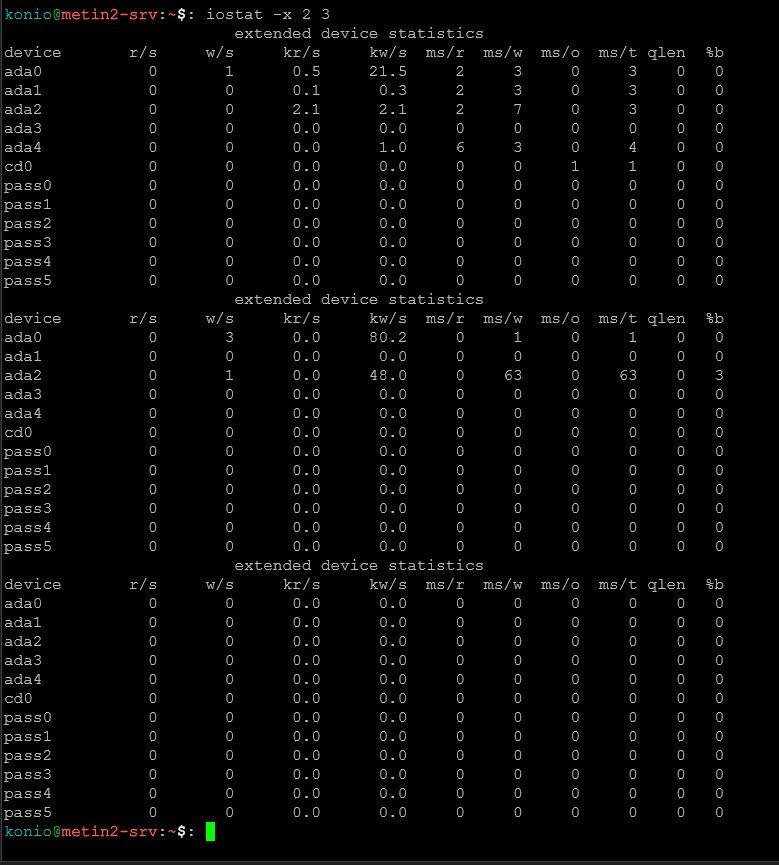
Interpretacja wyniku:
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz %util sda 10.5 5.2 0.50 0.25 0.5 1.2 5% 10% 2.5ms 5.0ms 0.08 8.5%
r/s– read operations per secondw/s– write operations per secondrMB/s / wMB/s– megabajty czytane/zapisywane na sekundę%util– procent wykorzystania dysku (>80% = problem)r_await / w_await– średni czas oczekiwania operacji (wysoki = wolny dysk)
Komenda sar – System Activity Reporter
sar z pakietu sysstat to kompleksowe narzędzie do monitorowania systemu. Może zbierać dane historyczne.
sar -u 2 5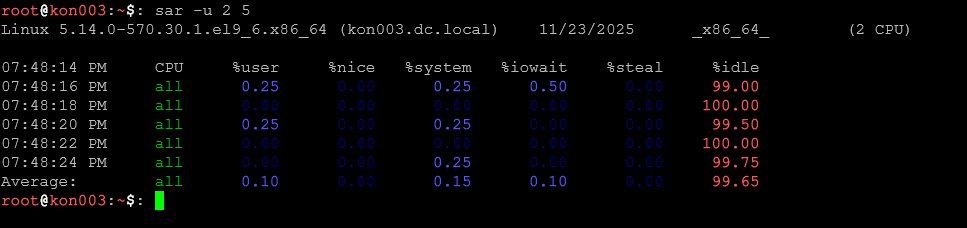
Statystyki CPU co 2 sekundy, 5 razy.
sar -r 2 5
Statystyki pamięci.
sar -d 2 5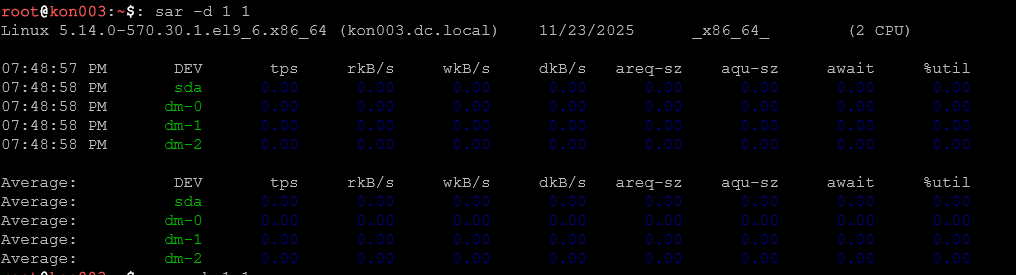
Statystyki dysków (podobnie jak iostat).

sar -b 2 5I/O i przełączenia stron (page faults).

Monitorowanie swap activity – problem w systemach
vmstat 1 | grep -v procs | awk '$7 > 0 || $8 > 0 { print "SWAP AKTYWNY!", $0 }'
Ostrzeżenie gdy system zaczyna pisać do swap
watch -n 1 'vmstat 1 2 | tail -1'Ciągłe monitorowanie najnowszych danych vmstat.

Praktyczne problemy z pamięcią i jak je diagnozować
Problem: System powolny, dużo swap activity
# 1. Sprawdź dostępną pamięć free -h
2. Sprawdź swap
vmstat 1 5 | grep -E 'si|so'
3. Szukaj procesów zużywających pamięć
ps aux --sort=-%mem | head -20
4. Sprawdź I/O wait
iostat -x 1 5Problem: Serwer Metin2 (MT2SRV) zajmuje za dużo pamięci
# Monitoruj samo server gry watch -n 1 'ps aux | grep -E "game|db|auth" | awk "{print \$2, \$4, \$11}"'
Jeśli pamięć rośnie bezustannie (memory leak)
ps aux | grep game | awk '{print $2}' # Uzyskaj PID
cat /proc/[PID]/status | grep VmRSS # Aktualna pamięć tego procesuWyzwalanie alertów przy braku pamięci
#!/bin/bash AVAILABLE=$(free -h | awk '/^Mem:/ {print $7}' | tr -d 'G') if (( $(echo "$AVAILABLE < 1" | bc -l) )); then echo "ALARM: Pamięć poniżej 1GB!" fiUprawnienia plików i katalogów - chmod i chowa
1. Podstawy modelu uprawnień
Każdy plik i katalog ma przypisane uprawnienia dla trzech grup użytkowników:
- u (user) – właściciel pliku
- g (group) – grupa, do której należy plik
- o (others) – wszyscy pozostali użytkownicy
Dla każdej z tych grup można przypisać trzy typy uprawnień:
- r (read) – prawo do odczytu
- w (write) – prawo do zapisu/modyfikacji
- x (execute) – prawo do wykonania (dla plików) lub wejścia (dla katalogów)
2. Wyświetlanie uprawnień
ls -l plik.txtWyświetla szczegółowe informacje, w tym uprawnienia w formacie:
-rwxr-xr--Gdzie:
- Pierwszy znak: typ pliku (
-zwykły plik,dkatalog,llink symboliczny) - Kolejne 3 znaki: uprawnienia właściciela (
rwx) - Kolejne 3 znaki: uprawnienia grupy (
r-x) - Ostatnie 3 znaki: uprawnienia innych (
r--)
3. Komenda chmod – zmiana uprawnień
Format symboliczny (literowy):
chmod u+x skrypt.shDodaje właścicielowi prawo wykonywania pliku skrypt.sh.
chmod g-w dokument.txtOdbiera grupie prawo do zapisu w pliku dokument.txt.
chmod o+r raport.pdfDodaje innym użytkownikom prawo do odczytu pliku raport.pdf.
chmod a+r plik.txtDodaje prawo do odczytu dla wszystkich (właściciel, grupa, inni).
chmod go-rwx prywatny.txtOdbiera grupie i innym wszystkie uprawnienia do pliku.
Format numeryczny (oktalny):
Każde uprawnienie ma wartość liczbową:
- r (read) = 4
- w (write) = 2
- x (execute) = 1
Sumując wartości, otrzymujemy kod uprawnień dla każdej grupy:
- 7 = rwx (4+2+1)
- 6 = rw- (4+2)
- 5 = r-x (4+1)
- 4 = r-- (4)
- 0 = --- (brak uprawnień)
chmod 755 skrypt.shWłaściciel: rwx (7), grupa: r-x (5), inni: r-x (5).
chmod 644 dokument.txtWłaściciel: rw- (6), grupa: r-- (4), inni: r-- (4).
chmod 700 prywatny_skrypt.shTylko właściciel ma pełny dostęp, inni nie mają żadnych uprawnień.
4. Rekurencyjna zmiana uprawnień
chmod -R 755 /var/www/stronaOpcja -R (recursive) zmienia uprawnienia dla katalogu i wszystkich plików oraz podkatalogów w nim zawartych.
chmod -R u+rwX /home/user/dokumentyDuże X dodaje prawo wykonywania tylko do katalogów i plików, które już mają to prawo dla kogokolwiek.
5. Komenda chown – zmiana właściciela i grupy
chown user plik.txtZmienia właściciela pliku na użytkownika user.
chown user:grupa plik.txtZmienia właściciela na user i grupę na grupa.
chown :grupa plik.txtZmienia tylko grupę (właściciel pozostaje bez zmian).
chown -R www-data:www-data /var/wwwRekurencyjnie zmienia właściciela i grupę dla całego katalogu i jego zawartości.
6. Praktyczne przykłady zastosowań
# Nadanie uprawnień wykonywania dla skryptu
chmod +x deploy.sh
# Zabezpieczenie pliku konfiguracyjnego (tylko właściciel może czytać i pisać)
chmod 600 config.ini
# Typowe uprawnienia dla katalogu www
chmod -R 755 /var/www/html
chown -R www-data:www-data /var/www/html
# Odebranie wszystkich uprawnień innym użytkownikom
chmod go-rwx /home/user/tajne_dane
# Sprawdzenie uprawnień przed i po zmianie
ls -l plik.txt
chmod 644 plik.txt
ls -l plik.txt
Atrybuty plików i katalogów
Wprowadzenie:
Poza standardowymi uprawnieniami (rwx), system Linux oferuje dodatkowe mechanizmy kontroli dostępu do plików i katalogów. Należą do nich pliki ukryte oraz rozszerzone atrybuty zarządzane poleceniem chattr.
1. Pliki ukryte w systemie Linux/Unix
Co to są pliki ukryte?
W systemach Unix/Linux plikami ukrytymi nazywamy pliki i katalogi, których nazwa zaczyna się od kropki (.). Są one domyślnie niewidoczne przy standardowym wywoływaniu ls. Pliki ukryte często zawierają konfiguracje użytkownika lub aplikacji.
Wyświetlanie plików ukrytych:
ls -aPokazuje wszystkie pliki, w tym ukryte.
ls -laSzczegółowy widok ze wszystkimi plikami, w tym ukrytymi.
Przykłady typowych plików ukrytych:
.bashrc– konfiguracja powłoki bash.bash_profile– konfiguracja przy logowaniu.ssh/– katalog z kluczami SSH.gitignore– plik konfiguracyjny git.vimrc– konfiguracja edytora vim
Tworzenie ukrytego pliku:
touch .ukryty_plik.txtWystarczy, że nazwa zaczyna się od kropki.
2. Rozszerzone atrybuty plików – chattr
Co to są rozszerzone atrybuty?
Rozszerzone atrybuty to dodatkowe flagi kontrolujące zachowanie plików na poziomie systemu plików. Pozwalają one na bardziej precyzyjną kontrolę niż standardowe uprawnienia rwx. Są obsługiwane głównie w systemach plików ext2, ext3, ext4.
Komenda chattr – zmiana atrybutów:
chattr +i plik.txtUstawia atrybut niezmienności (immutable). Plik nie może być modyfikowany, usuwany, zmieniany ani przenoszony – nawet przez użytkownika root!
chattr -i plik.txtUsuwa atrybut niezmienności.
3. Najważniejsze atrybuty chattr
Atrybut i (immutable – niezmienny):
chattr +i /etc/ważny_config.confPlik nie może być w żaden sposób modyfikowany. Przydatne do ochrony krytycznych plików konfiguracyjnych przed przypadkową zmianą.
Atrybut a (append only – tylko dopisywanie):
chattr +a /var/log/aplikacja.logPlik może być tylko rozszerzany (dopisywanie na końcu), ale nie można modyfikować ani usuwać istniejącej zawartości. Idealne dla plików logów.
Atrybut c (compressed – kompresowany):
chattr +c duży_plik.txtJądro automatycznie kompresuje plik na dysku (jeśli system plików to obsługuje).
Atrybut d (no dump – pomijany w backup):
chattr +d cache.tmpPlik jest pomijany przez narzędzie dump podczas tworzenia kopii zapasowej.
Atrybut s (secure deletion – bezpieczne usuwanie):
chattr +s tajny_dokument.txtPrzy usuwaniu pliku, jego bloki na dysku są nadpisywane zerami, co utrudnia odzyskanie danych.
Atrybut u (undeletable – możliwy do odzyskania):
chattr +u ważny_plik.txtSystem zachowuje informacje pozwalające na odzyskanie pliku po usunięciu (jeśli system plików to wspiera).
4. Komenda lsattr – wyświetlanie atrybutów
lsattr plik.txtPokazuje aktualne atrybuty pliku.
lsattr -d katalog/Pokazuje atrybuty samego katalogu (a nie jego zawartości).
lsattr -aPokazuje atrybuty wszystkich plików, w tym ukrytych.
Przykładowy wynik:
$ lsattr plik.txt
----i---------e----- plik.txtLitera i oznacza atrybut immutable.
5. Rekurencyjna zmiana atrybutów
chattr -R +i /etc/config/Opcja -R (recursive) stosuje atrybut do wszystkich plików i podkatalogów.
6. Praktyczne przykłady zastosowań
# Ochrona pliku konfiguracyjnego przed modyfikacją
sudo chattr +i /etc/ssh/sshd_config
# Teraz nawet root nie może go zmienić bez usunięcia atrybutu
# Sprawdzenie atrybutów
lsattr /etc/ssh/sshd_config
# Aby móc edytować, trzeba najpierw usunąć atrybut
sudo chattr -i /etc/ssh/sshd_config
# Zabezpieczenie pliku logów – tylko dopisywanie
sudo chattr +a /var/log/aplikacja.log
# Ochrona całego katalogu przed usunięciem
sudo chattr -R +i /opt/produkcja/
# Weryfikacja atrybutów wszystkich plików w katalogu
lsattr -a /home/user/
7. Ważne uwagi
- Rozszerzone atrybuty działają na poziomie systemu plików – nie wszystkie systemy plików je obsługują
- Tylko użytkownik root może zmieniać większość atrybutów
- Atrybuty są niezależne od standardowych uprawnień Unix (rwx)
- Podczas przenoszenia plików między systemami atrybuty mogą zostać utracone
- Warto dokumentować użycie atrybutów, aby inni administratorzy wiedzieli o ich zastosowaniu
Obsługa komendy sed
Co to jest sed?
sed (stream editor) to narzędzie do przetwarzania tekstu na poziomie linii, działające linia po linii. Pozwala na automatyczną edycję plików lub strumieni tekstu bez konieczności otwierania ich w interaktywnym edytorze.
Podstawowa składnia polecenia
sed [opcje] 'polecenia' plikW poleceniu sed wykonujemy polecenia edycyjne na każdej linii pliku lub strumienia.
Najważniejsze polecenia sed używane w przykładach
s/wzorzec/tekst/– zamiana pierwszego wystąpienia wzorca w linii na podany tekst.s/wzorzec/tekst/g– zamiana wszystkich wystąpień wzorca w linii (opcjag– globalnie).d– usunięcie linii (np./^#/dusuwa linie zaczynające się od #).p– wyświetlenie linii (często stosowane z opcją-n, by wyświetlić tylko wybrane linie).a– dodanie tekstu po bieżącej linii.i– wstawienie tekstu przed bieżącą linią.
Wyjaśnienie składni zamiany (substytucji) s/// oraz znaków
s– instrukcja “substitute” (zamień).- Separator w
s///zwykle to znak/, ale może być dowolny (np.#) aby uniknąć uciekania/w zamienianych wzorcach. \'– apostrofy służą do ujęcia polecenia tak, by uniknąć interpretacji przez powłokę.g– oznacza "globalnie", czyli zamień wszystkie wystąpienia.d– oznacza "delete", usuń linie pasujące do wzorca.
Obsługa znaków specjalnych - escape w sed
\\– backslash musi być podwójnie ucieczony\\\\w poleceniach.\.– kropka oznacza dowolny znak, żeby faktycznie wyszukać kropkę musimy ją uciec.\*,\^,\$,\[ \]– także mają specjalne znaczenie, wymagają escape.- Alternatywnie możemy zmienić separator
s/old/new/na np.s#old#new#, co ułatwia pracę ze ścieżkami.
Przykłady:
Zamiana adresu IP na inny:
sed 's/192\.168\.1\.1/10.0.0.1/g' plik.confZamienia wszystkie wystąpienia adresu IP 192.168.1.1 na 10.0.0.1, kropki są escape'owane.
Zamiana ścieżek za pomocą innego separatora:
sed 's#/var/www/html#/srv/www#g' plik.confUżycie znaku # zamiast / jako separatora pozwala uniknąć escape'ów w ścieżkach.
Komentowanie zakresu linii:
sed '10,20s/^/#/' plik.confDodaje znak # na początku linii od 10 do 20.
Odkomentowanie zakresu linii:
sed '10,20s/^#//' plik.confUsuwa znak # z początku linii od 10 do 20.
Usuwanie pustych linii:
sed '/^$/d' plik.confUsuwa linie całkowicie puste.
Podwajanie backslash:
sed 's/\\/\\\\/g' plik.confZamienia pojedynczy znak \ na podwójny \\ (używane np. przy generowaniu ścieżek w skryptach).
Zamiana z grupami przechwytywania:
sed 's/\(foo\) \(bar\)/\2 \1/' plik.confZamienia wystąpienie "foo bar" na "bar foo", gdzie \( ... \) wskazuje grupy tekstu, a \1, \2 odwołują się do nich w zamianie.
Zaawansowana zamiana adresu IP z regexp:
sed 's/\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}/10.0.0.1/g' plik.confZamienia dowolny adres IPv4 (4 liczby 0-999 rozdzielone kropkami) na 10.0.0.1.
Edycja pliku in-place na FreeBSD:
sed -i '' 's/stary/nowy/g' plik.confPodmienia wszystkie wystąpienia "stary" na "nowy" bez tworzenia kopii zapasowej, ważne jest wymienienie '' po -i.
Obsługa awk
AWK to potężne narzędzie do przetwarzania i analizy tekstu, szczególnie przydatne do pracy z danymi podzielonymi na kolumny. Pozwala na wyszukiwanie, filtrowanie, formatowanie i agregację danych z plików tekstowych lub wyników innych poleceń.
Podstawowa składnia AWK
awk 'warunek { działania }' plikWyjaśnienie:
warunek– wyrażenie logiczne lub wzorzec tekstowy, który musi być spełniony, aby wykonaćdziałania(np. filtrowanie linii).{ działania }– polecenia wykonywane na liniach spełniających warunek (np. wypisanie wybranych kolumn).
Odwołania do pól i zmienne w AWK
$0 # cała linia tekstu wejściowego
$1, $2, … # kolejne kolumny/ pola w linii (domyślnie pola rozdzielone spacjami)
NR # numer bieżącego wiersza (count)
NF # liczba pól w bieżącej liniiWyjaśnienia:
AWK dzieli każdą linię na pola (domyślnie na spacje/tabulacje). Użycie $1 zwraca pierwszą kolumnę, $2 drugą itd. Zmienna NR oznacza numer bieżącej linii, a NF ilość kolumn w bieżącym wierszu.
Przykłady użycia AWK – pojedyncze komendy
1. Wyświetl pierwszą i trzecią kolumnę każdego wiersza:
awk '{ print $1, $3 }' plik.txt2. Wyświetl linie, których pierwsza kolumna równa jest "error":
awk '$1 == "error" { print $0 }' plik.txt3. Sumowanie wartości w kolumnie numer 2:
awk '{ suma += $2 } END { print suma }' plik.txtWyjaśnienie: dla każdej linii dodaj wartość pola 2 do zmiennej suma, a na końcu END wypisz wynik.
4. Wypisz numer linii oraz zawartość linii:
awk '{ print NR, $0 }' plik.txtWyrażenia regularne (regexp) w AWK
AWK wspiera wyrażenia regularne do dopasowywania tekstu. Można je stosować w warunkach:
awk '/pattern/ { print $0 }' plik.txtZnajduje i wypisuje linie zawierające pattern.
Można łączyć takie dopasowanie z innymi warunkami i operatorami:
awk '$3 ~ /error/' plik.txtWypisuje linie, w których trzecia kolumna zawiera słowo "error".
awk '$2 !~ /^[0-9]+$/' plik.txtWypisuje linie, gdzie druga kolumna nie składa się wyłącznie z cyfr.
Przetwarzanie i filtrowanie danych z AWK – bardziej rozbudowane przykłady
Wyświetlanie wierszy, gdzie kolumna 5 jest większa niż 100:
awk '$5 > 100 { print $0 }' plik.txtFormatowane wypisywanie danych (np. kolumny 1 i 3 oddzielone tabulatorem):
awk '{ printf "%s\t%s\n", $1, $3 }' plik.txtPodliczanie wystąpień unikalnych wartości w kolumnie 3:
awk '{ counts[$3]++ } END { for (val in counts) print val, counts[val] }' plik.txtWywołania specjalne i kontrola przepływu
AWK pozwala na tworzenie bloków BEGIN i END do wykonania instrukcji przed lub po przeczytaniu wszystkich linii:
awk 'BEGIN { print "Start przetwarzania" }
{ print $1 }
END { print "Koniec przetwarzania" }' plik.txtPętla i warunki są typowe dla języków programowania, np.:
awk '{
if ($2 > 100)
print $0
else
next
}' plik.txtOgólne komendy BASH
Sprawdzanie zombie procesów
printf "PID PPID USER STAT CMD\n"; ps -eo pid,ppid,user,stat,command | awk '$4 ~ /Z/' 
Czyszczenie SWAP
Wszystkie komendy wykonuje z CLI bash / sh z uprawnieniami root (sudo)
Komendy weryfikujące status wolnej przestrzeni w pamięci SWAP
Sprawdzenie całego meminfo, które zawiera wszelkie informacje o pamieci na systemie linux
cat /proc/meminfo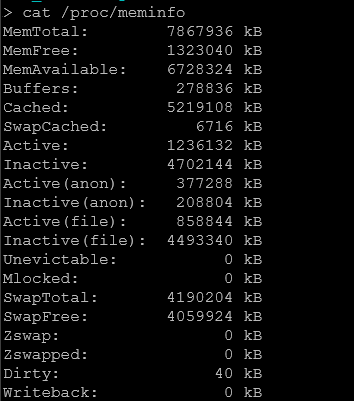
Komenda free sprawdza aktualnie zaalakowaną oraz wolną pamięć operacyjną
free -m
Komendy wykonujące oczyszczenia pamięci podręcznej
Oczyszczenie pamięci podręcznej stronicowania (pagecache)
sync; echo 1 > /proc/sys/vm/drop_cachesOczyszczenie pamięci podręcznej katalogów (dentries) i i-węzłów (inodes)
sync; echo 2 > /proc/sys/vm/drop_cachesOczyszczenie całej pamięci podręcznej (pagecache, dentries i inodes)
sync; echo 3 > /proc/sys/vm/drop_caches Wyłączenie SWAP
swapoff -a Włączenie SWAP
swapon -a Kombinacja komend - wyłączenie i włączenie SWAP
sudo swapoff -a && sudo swapon -aSprawdzenie czy user może korzystać z sudo
Komendy wykonujemy z CLI bash / sh z uprawnieniami root (sudo)
Weryfikacja użytkownika pod kątem możliwości korzystania z sudo weryfikujemy komendą:
sudo -l -U NazwaUżytkownikaPrzykładowy wynik:

Sprawdzenie daty wygasania hasła użytkownika
Komendy wykonujemy z CLI bash / sh z uprawnieniami root (sudo)
Weryfikacja użytkownika pod kątem wygasanie jego hasła / konta weryfikujemy komendą:
chage -l NazwaUżytkownikaPrzykładowy wynik:

Sieć
Przekierowanie ruchu sieciowego pomiędzy kartami sieciowymi
Włączenie przekazywania pakietów (IP Forwarding)
Na początku należy sprawdzić konfigurację sysctl
sudo vim /etc/sysctl.confi szukamy wpisu:
net.ipv4.ip_forward = 1Przeładowujemy konfigurację
sudo sysctl -p
i sprawdzamy czy opcja jest aktywna:
cat /proc/sys/net/ipv4/ip_forward
Jeśli wynik to 1, przekazywanie pakietów jest włączone.
Konfiguracja NAT (SNAT) poprzez IPTABLES
sudo iptables -t nat -I POSTROUTING -p all -s AdresacjaIPskąd ! -d AdresacjaIPdokąd -j SNAT --to-source JakimIPmaWychodzićPrzykład z całymi podsieciami:
sudo iptables -t nat -I POSTROUTING -p all -s 172.18.0.0/29 ! -d 172.18.0.0/29 -j SNAT --to-source 10.95.227.9Co robi ta reguła?
- iptables → komenda którą nanosimy zmiany
- -t nat → Modyfikuje tablicę NAT.
- -I POSTROUTING → Wstawia regułę do łańcucha POSTROUTING, czyli po podjęciu decyzji o routingu.
- -p all → Dotyczy wszystkich protokołów (TCP, UDP, ICMP itp.).
- -s 172.18.0.0/29 → Ogranicza regułę do ruchu wychodzącego z tej podsieci.
- ! -d 172.18.0.0/29 → Nie dotyczy ruchu wewnątrz tej samej podsieci (eliminuje NAT dla ruchu lokalnego).
- -j SNAT --to-source 10.95.227.9 → Zamienia źródłowy adres IP na 10.95.227.9, aby umożliwić komunikację z innymi sieciami.
Sprawdzamy czy reguła została dodana:
sudo iptables -t nat -L -v -n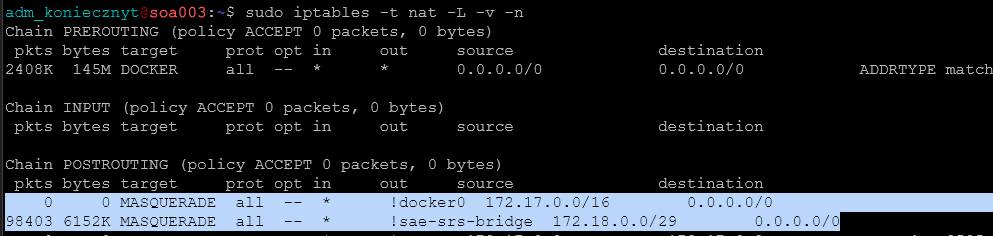
Zapisujemy konfigurację:
sudo service iptables savesudo iptables-save | sudo tee /etc/sysconfig/iptables
Skrypt tworzący reguły przekierowania dla portów mailowych
Uruchamiamy na systemie proxy:
#!/bin/bash
# Sposób użycia: sudo ./mail_routing.sh <docelowy_adres_IP>
#
# Przykład: sudo ./mail_routing.sh 192.168.1.138
# Sprawdzenie, czy podano adres IP
if [ -z "$1" ]; then
echo "Użycie: $0 <docelowy_adres_IP>"
exit 1
fi
TARGET_IP="$1"
# Lista standardowych portów pocztowych
MAIL_PORTS=(25 465 587 143 993 110 995)
echo "Usuwanie poprzednich reguł..."
iptables -t nat -F PREROUTING
iptables -F FORWARD
iptables -t nat -F POSTROUTING
echo "Dodawanie nowych reguł przekierowania dla adresu: $TARGET_IP"
# Dodawanie reguł przekierowania dla każdego portu
for PORT in "${MAIL_PORTS[@]}"; do
echo "Przekierowanie portu $PORT na $TARGET_IP:$PORT"
iptables -t nat -A PREROUTING -p tcp --dport $PORT -j DNAT --to-destination $TARGET_IP:$PORT
iptables -A FORWARD -p tcp --dport $PORT -d $TARGET_IP -j ACCEPT
iptables -t nat -A POSTROUTING -p tcp -d $TARGET_IP --dport $PORT -j MASQUERADE
done
# Zapisywanie reguł, aby przetrwały restart systemu
echo "Zapisywanie reguł iptables..."
iptables-save > /etc/sysconfig/iptables 2>/dev/null || service iptables save 2>/dev/null
echo "Konfiguracja zakończona! Sprawdzenie reguł:"
iptables -t nat -L -v -n
iptables -L -v -n
Przykładowa część wyniku:
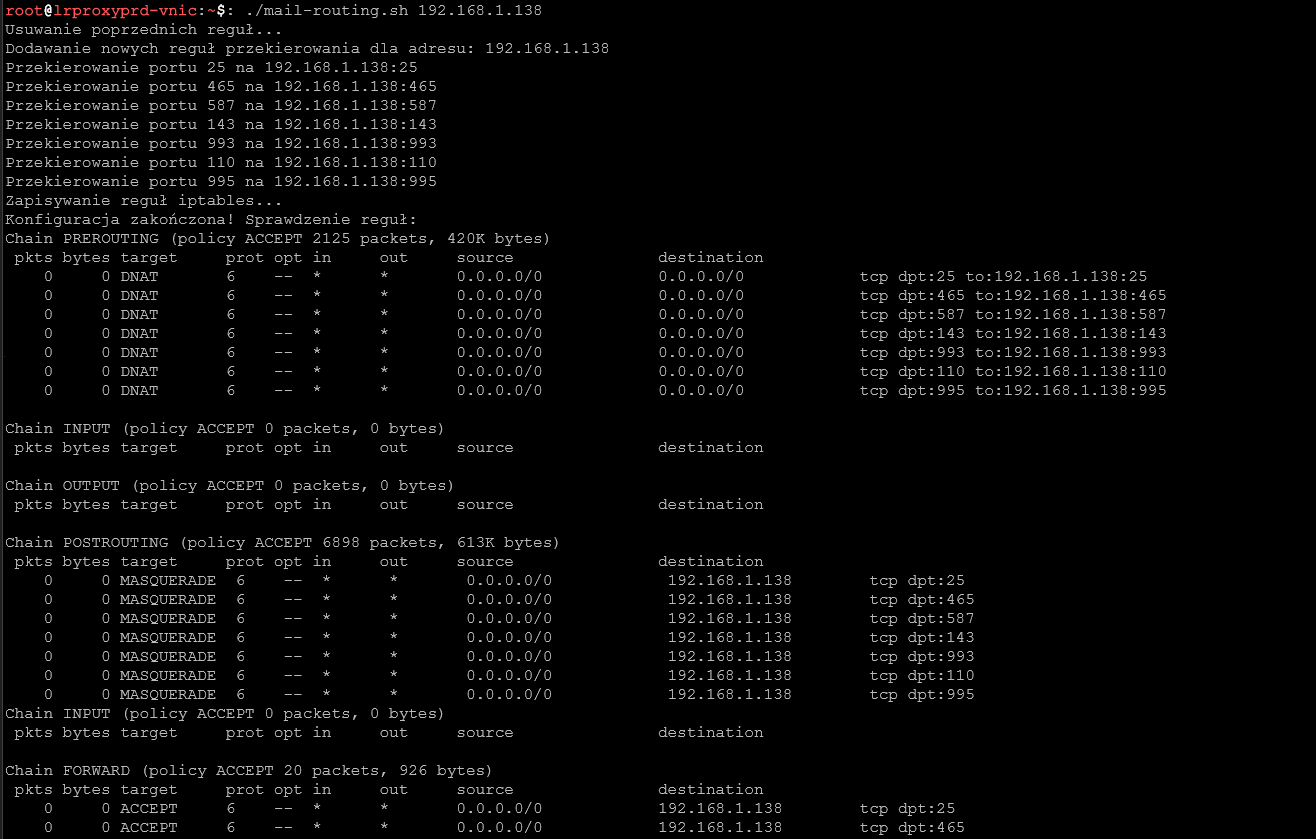
Weryfikacja zapory sieciowej (firewalld) oraz dodanie wyjątków
Komendy wykonujemy z CLI bash / sh z uprawnieniami root (sudo)
Sprawdzenie wszystkich reguł firewallD:
sudo firewall-cmd --list-allDodanie portu:
sudo firewall-cmd --add-port=NumerPortu/tcp --permanentDodanie portu ograniczając do jednej zone
sudo firewall-cmd --zone=NazwaZony --add-port=NumerPortu/tcp --permanentDodanie usługi:
sudo firewall-cmd --permanent --add-service=NazwaServicePo zmianach należy przeładować firewallD:
sudo firewall-cmd --reloadCo to jest "rich rule" w firewallD?
Rich rules to zaawansowane reguły w firewallD, które pozwalają na bardziej precyzyjne definiowanie zasad niż standardowe strefy i usługi. Umożliwiają m.in.:
- Filtrowanie według protokołu, adresów IP, portów, interfejsów
- Ustalanie kierunku ruchu (input, output, forward)
- Logowanie i kontrolę pasma
Przykład dodania rich-rule:
sudo firewall-cmd --add-rich-rule='rule protocol value="NazwaProtokołu" accept' --permanentPrzykład wpuszczenia ruchu ssh z jednego adresu IP
sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.1.100" service name="ssh" accept' --permanentPo zmianach należy przeładować firewallD:
sudo firewall-cmd --reloadSpecyficzne dla Rodziny Enterprise Linux
Usunięcie nieużywanych kerneli
Komendy wykonujemy w CLI bash bądź sh jako user z uprawnieniami sudo / root.
Sprawdzenie który kernel jest używany aktualnie. Powinien on być najnowszy z listy wynikowej
sudo rpm -q kernel | sed "/$(uname -r)/ s/$/ ACTIVE/"Przykład:

Komenda usunięcia nieużywanych kerneli w starszych systemach operacyjnych EL (wersje 5-7)
sudo package-cleanup --oldkernels --count=1 Komenda usunięcia nieużywanych kerneli w nowszych systemach operacyjnych EL 8+
sudo dnf remove --oldinstallonly --setopt installonly_limit=2 kernelPrzykład:
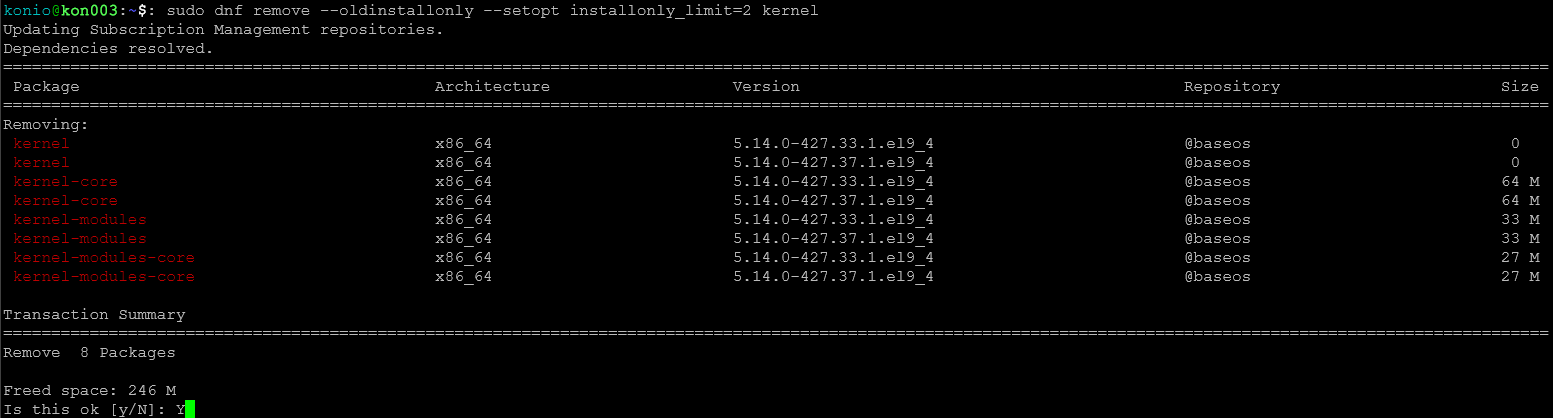
Usunięcie nieużywanych kerneli ręcznie
Przechodzimy do katalogu gzie obrazy kernela się znajdują:
cd /boot find . -name '*numer_starej_wersji_kernela*' Usuwamy wszystkie wystąpienia znalezione powyższą komendą
sudo rm nazwa_plikuRęczna instalacja repozytorium EPEL (Extra Packages for Enterprise Linux)
EPEL (Extra Packages for Enterprise Linux) to repozytorium, które dostarcza dodatkowe pakiety oprogramowania, które nie są dostępne w oficjalnych repozytoriach Red Hat Enterprise Linux (RHEL) oraz jego klonów, takich jak CentOS i Rocky Linux.
Komendy wykonujemy w CLI bash bądź sh jako user z uprawnieniami sudo / root.
Najpierw oczywiście sprawdzamy podstawową komendę:
dnf install epel-releaseDla niektórych dystrybucji warto doinstalować dodatkowe repozytorium CBR (CodeReady Builder).
Red Hat Enterprise Linux 9:
subscription-manager repos --enable codeready-builder-for-rhel-9-$(arch)-rpms
dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm Rocky Linux 9:
dnf config-manager --set-enabled crb
dnf install epel-release RHEL 8:
subscription-manager repos --enable codeready-builder-for-rhel-8-$(arch)-rpms
dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm Rocky Linux 8:
dnf config-manager --set-enabled powertools
dnf install epel-releaseRHEL 7:
subscription-manager repos --enable rhel-*-optional-rpms \
--enable rhel-*-extras-rpms \
--enable rhel-ha-for-rhel-*-server-rpms
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
subscription-manager repos --disable=rhel-7-server-eus-optional-rpms CentOS 7:
yum install epel-release Podział aktualizacji pakietów pod względem nazw pakietów
Podział aktualizacji na mniejsze partie może być wymagany jeżeli wielkość paczki aktualizacyjnej przekracza dostępne miejsce na dyskach.
Komendy wykonujemy w CLI bash bądź sh jako user z uprawnieniami sudo / root.
sudo dnf update $(dnf list updates | awk '/^[LITERASTARTOWA-LITERAKOŃCOWA1]/ {print $1}')
sudo dnf update $(dnf list updates | awk '/^[LITERAKOŃCOWA1-LITERAKOŃCOWA2]/ {print $1}') Przykład aktualizacji ograniczonej literami od a do c
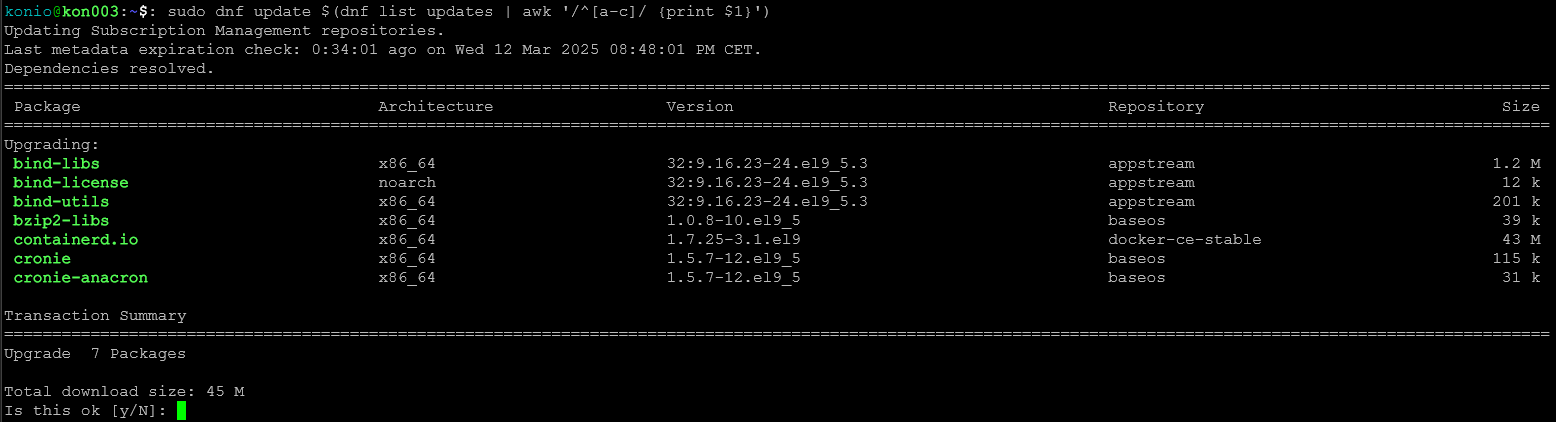
Przykład podziału aktualizacji na pół:
sudo dnf update $(dnf list updates | awk '/^[a-j]/ {print $1}')
sudo dnf update $(dnf list updates | awk '/^[k-z]/ {print $1}') Doinstalowanie obsługi SysV na Rocky 9
W systemie Rocky Linux 9 niektóre aplikacje mogą nadal korzystać "pod maską" z SysV, mimo że przy instalacji utworzyły się usługi systemd. Przykładem takiej aplikacji jest Networker, problem pojawia się, gdy chcemy włączyć autostart usługi networker.service:

W takim wypadku należy wykonać następujące kroki:
-
Skopiować zawartość /etc/init.d do osobnej lokalizacji.
-
Usunąć katalog /etc/init.d
-
Zainstalować paczki initscripts oraz chkconfig:
dnf install -y initscripts chkconfig -
Na koniec należy przywrócić wcześniejszą zawartość /etc/init.d
Po wykonaniu powyższych kroków można powtórzyć próbę włączenia autostartu usługi. Teraz komenda powinna wykonać się prawidłowo.

Instalacja systemu Rocky Linux 9 z nazwaniem odpowiednio VG oraz LV
Po uruchomieniu instalatora wybieramy odpowiedni język:
I wciskamy kombinację klawiszy
CTRL + ALT + F3Przeniesie nas to do sesji terminalowej w której będziemy mogli dowolnie zarządzać dyskami. Możemy zweryfikować wykrywane dyski poprzez List Block Devices:
lsblk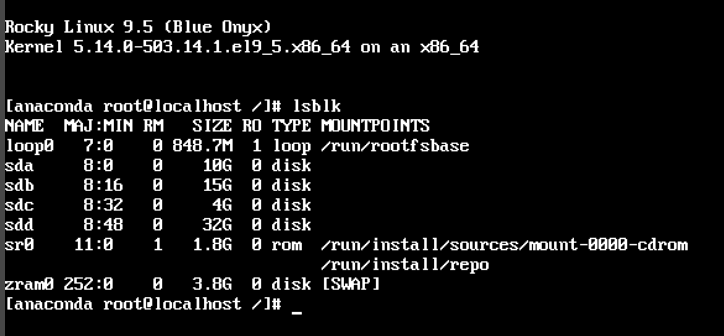
Na początku musimy utworzyć phisical device poprzez komendę pvcreate
pvcxreate /dev/sdXPrzykład wykonania komendy
pvcreate /dev/sda
Tworzymy resztę wymaganych urządzeń fizycznych:
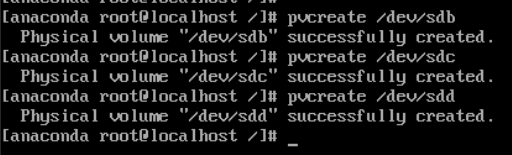
Kolororwanie BASH prompt (zmiana PS1)
Aby zmiany działały dla pojedyńczego usera zmieniamy plik .bash_profile w HOME usera "~"
cd ~
vim .bash_profileSerwery testowe:
# User specific environment and startup programs
export PS1="\[\033[00;36m\]\u\[\033[00;32m\]@\[\033[01;32m\]\h\[\033[00m\\]:\[\033[01;34m\]\w\[\033[01;37m\]$\[\033[00m\]: " Serwery produkcyjne:
# User specific environment and startup programs
export PS1="\[\033[00;36m\]\u\[\033[00;32m\]@\[\033[1;31m\]\h\[\033[00m\]:\[\033[1;31m\]\w\[\033[1;37m\]$\[\033[00m\]: " User ROOT, serwery TST:
# Root-User specific environment and startup programs
export PS1="\[\033[1;31m\]\u\[\033[1;37m\]@\[\033[01;32m\]\h\[\033[00m\\]:\[\033[01;34m\]\w\[\033[01;37m\]#\[\033[00m\]: "User ROOT, serwery PRD:
# Root-User specific environment and startup programs
export PS1="\[\033[1;31m\]\u\[\033[1;37m\]@\[\033[1;31m\]\h\[\033[00m\]:\[\033[1;31m\]\w\[\033[1;37m\]#\[\033[00m\]: " Full Violet
# FoolsTheory-User specific environment and startup programs FoolsTheory Violet:
export PS1="\[\033[1;35m\]\u\[\033[1;37m\]@\[\033[1;35m\]\h\[\033[00m\]:\[\033[1;35m\]\w\[\033[1;37m\]$\[\033[00m\]: "Można także zmieniać w formacie HEX:
# FoolsTheory-User specific environment and startup programs FoolsTheory Violet:
export PS1="\[\e[38;2;176;132;204m\]\u\[\e[0m\]@\[\e[38;2;176;132;204m\]\h:\w\[\e[0m\] \$ "Dodanie systemu Linux do domeny AD poprzez RealmD
OS musi rozwiązywać nazwy domeny i mieć odpowiedni ruch puszczony
Instalujemy zestaw paczek:
sudo dnf install sssd realmd oddjob oddjob-mkhomedir adcli samba-common samba-common-tools krb5-workstation openldap-clients vim net-tools telnet tree -yDodajemy system do domeny
realm join --user=NazwaUseraWDomenie NazwaDomeny
Dodajemy userów z domeny jako userzy z uprawnieniami do sudo :
visudododajemy
%GrupaWdomenie@domena.local ALL=(ALL) NOPASSWD:ALL
Edytujemy plik sssd dla lepszej kompatybilności logowania:
vim /etc/sssd/sssd.confWeryfikujemy czy nasz plik wygląda tak:
[sssd]
domains = NazwaDomeny
config_file_version = 2
services = nss, pam
default_domain_suffix = NazwaDomeny
[domain/NazwaDomeny]
default_shell = /bin/bash
krb5_store_password_if_offline = True
cache_credentials = True
krb5_realm = FOOLSTHEORY.LOCAL
realmd_tags = manages-system joined-with-adcli
id_provider = ad
fallback_homedir = /home/%u@%d
ad_domain = NazwaDomeny
use_fully_qualified_names = True
ldap_id_mapping = True
access_provider = ad
ad_hostname = NazwaKontroleraDC
dyndns_update = true
dyndns_refresh_interval = 43200
dns_update_ptr = true
dynds_ttl = 3600
dyndns_auth = GSS-TSIGRestartujemy SSSD

Po tych operacjach można logować się poprawnie:
Instalacja ODBC MSSQL na dystrybucjach RHEL
Komendy można wykonywać całościowo jako blok tekstu
if ! [[ "7 8 9" == *"$(grep VERSION_ID /etc/os-release | cut -d '"' -f 2 | cut -d '.' -f 1)"* ]];
then
echo "RHEL $(grep VERSION_ID /etc/os-release | cut -d '"' -f 2 | cut -d '.' -f 1) is not currently supported.";
exit;
fi
# Download the package to configure the Microsoft repo
curl -sSL -O https://packages.microsoft.com/config/rhel/$(grep VERSION_ID /etc/os-release | cut -d '"' -f 2 | cut -d '.' -f 1)/packages-microsoft-prod.rpm
# Install the package
sudo yum install packages-microsoft-prod.rpm
# Delete the file
rm packages-microsoft-prod.rpm
sudo yum remove unixODBC-utf16 unixODBC-utf16-devel #to avoid conflicts
sudo ACCEPT_EULA=Y yum install -y msodbcsql18
# optional: for bcp and sqlcmd
sudo ACCEPT_EULA=Y yum install -y mssql-tools18
echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc
source ~/.bashrc
# optional: for unixODBC development headers
sudo yum install -y unixODBC-develPo instalacji oczywiście należy skonfigurować plik połączeń
/etc/odbc.iniPrzykładowy config dla bazy MSSQL
# DSN dla Microsoft SQL Server (MSSQL) z ODBC Driver 18 i self-signed cert
[DSN_MSSQL]
Driver = ODBC Driver 18 for SQL Server
Server = sqlserver.example.local
Port = 1433
Database = your_database
TrustServerCertificate = Yes
# Uwierzytelnianie SQL (UID i PWD podaje Zabbix przez makra)
# Trusted_Connection=Yes # NIE aktywuj, jeśli nie masz Kerberosa
Przykładowe konfiguracje ODBC dla różnych baz danych
Wpisy powinny znajdować się w /etc/odbc.ini
Wymagane paczki:
unixODBC-devel
unixODBCDSN MSSQL
# DSN dla Microsoft SQL Server (MSSQL) z ODBC Driver 18 i self-signed cert
[DSN_MSSQL]
Driver = ODBC Driver 18 for SQL Server
Server = sqlserver.example.local
Port = 1433
Database = your_database
TrustServerCertificate = Yes
# Trusted_Connection=Yes # NIE aktywuj, jeśli nie masz KerberosaDSN PostgreSQL
# DSN dla PostgreSQL
[DSN_POSTGRES]
Driver = PostgreSQL Unicode
Servername = postgres.example.local
Port = 5432
Database = your_pgdbDSN MySQL/MariaDB
# DSN dla MariaDB/MySQL
[DSN_MARIA]
Driver = MariaDB ODBC 3.1 Driver
Server = mariadb.example.local
Port = 3306
Database = your_mariadb
# UID i PWD ustawia Zabbix przez makraDSN Oracle
# DSN dla Oracle
[DSN_ORACLE]
Driver = Oracle in OraClient12Home1
Server = oracle.example.local
Port = 1521
Database = ORCL
DSN Sybase
# DSN dla Sybase
[DSN_SYBASE]
Driver = Adaptive Server Enterprise
Server = sybase.example.local
Port = 5000
Database = your_sybase_dbMessage of the day - MOTD
Message Of The Day (MOTD)
Co to jest MOTD?
Message Of The Day (MOTD) to tekst wyświetlany po zalogowaniu do systemu, zazwyczaj zawiera powitanie lub najważniejsze informacje o systemie. W systemach Unix/Linux plik /etc/motd jest prostym plikiem tekstowym, który nie interpretuje poleceń, wyświetla jedynie statyczną zawartość.
Dlaczego plik /etc/motd nie może wykonywać poleceń?
Plik /etc/motd jest tylko zwykłym plikiem tekstowym i nie jest interpretowany jako skrypt ani polecenie. Aby mieć dynamiczne i kolorowe wiadomości, tworzymy osobny skrypt Bash, który jest wywoływany podczas logowania przez plik startowy powłoki.
Skrypt motd – sekcje i wyjaśnienia poleceń
#!/bin/bash#!/usr/local/bin/bashWyjaśnienie: Ścieżka do interpretera bash w systemach, gdzie bash jest zainstalowany w /usr/local/bin.
RED='\033[31m'
GREEN='\033[32m'
YELLOW='\033[33m'
CYAN='\033[36m'
RESET='\033[0m'
Wyjaśnienie: Definiujemy zmienne reprezentujące kody ANSI do kolorowania tekstu na terminalu.
echo -e "${CYAN} __ __ _____ ____ ____ ______ __"echo -e "| \\/ |_ _|___ \\/ ___|| _ \\ \\ / /"echo -e "| |\\/| | | | __) \\___ \\| |_) \\ \\ / / "echo -e "| | | | | | / __/ ___) | _ < \\ V / "echo -e "|_| |_| |_| |_____|____/|_| \\_\\ \\_/ ${RESET}"Wyjaśnienie: Wyświetlamy kolorowy napis ASCII art symbolizujący nazwę serwera w stylu retro. Polecenie echo -e interpretuje kody ucieczki dla kolorów, a instrukcje formatowania nadają kolor i resetują go po wyświetleniu.
LOAD=$(sysctl -n vm.loadavg | awk '{print $2, $3, $4}')Wyjaśnienie: Pobieramy średnie obciążenie CPU (load average) korzystając z sysctl, a awk wyciąga drugą, trzecią i czwartą wartość z wyniku (odpowiednio 1-, 5- i 15-minutowy load).
MEM_TOTAL=$(sysctl -n hw.physmem)
MEM_TOTAL_MB=$((MEM_TOTAL / 1024 / 1024))
PAGE_SIZE=$(sysctl -n hw.pagesize)
FREE_PAGES=$(sysctl -n vm.stats.vm.v_free_count)
MEM_FREE_BYTES=$((FREE_PAGES * PAGE_SIZE))
MEM_FREE_MB=$((MEM_FREE_BYTES / 1024 / 1024))Wyjaśnienie: Pobieramy całkowitą pamięć RAM i wyliczamy jej wartość w megabajtach. Następnie obliczamy ilość wolnej pamięci na podstawie liczby wolnych stron pamięci i rozmiaru strony. Wynik również jest konwertowany na megabajty.
echo -e "${YELLOW}Aktualne obciążenie CPU:${RESET} ${GREEN}${LOAD}${RESET}"
echo -e "${YELLOW}Pamięć całkowita:${RESET} ${GREEN}${MEM_TOTAL_MB} MB${RESET}"
echo -e "${YELLOW}Wolna pamięć:${RESET} ${GREEN}${MEM_FREE_MB} MB${RESET}"
Wyjaśnienie: Wyświetlamy pobrane wartości obciążenia CPU i pamięci RAM z kolorami, nadając nagłówkom i wartościom różne kolory dla czytelności.
df -h | awk -v CYAN="${CYAN}" -v GREEN="${GREEN}" -v RESET="${RESET}" '
NR>1 {
free_perc = 100 - gensub(/%/, "", "g", $5)
printf "%s%s%s: %s%d%%%s ", CYAN, $6, RESET, GREEN, free_perc, RESET
}
END {print ""}'
Wyjaśnienie: Polecenie df -h pokazuje rozmiary systemów plików w czytelnej formie. Za pomocą awk zliczamy procent wolnego miejsca (100 minus procent użycia z kolumny 5) i wyświetlamy punkt montowania (kolumna 6) razem z procentem wolnego miejsca, kolorując je odpowiednio.
count_process() {
ps aux | grep -w "$1" | grep -v grep | wc -l
}
COUNT_GAME=$(count_process "game")
COUNT_DB=$(count_process "db")
COUNT_AUTH=$(count_process "auth")
Wyjaśnienie: Definiujemy funkcję, która liczy liczbę procesów zawierających podany ciąg znaków w pełnej nazwie procesu. Następnie zliczamy liczbę obecnie działających procesów: "game", "db" oraz "auth".
color_status() {
if [ "$1" -gt 0 ]; then
echo -e "${GREEN}RUNNING (${1})${RESET}"
else
echo -e "${RED}NOT RUNNING${RESET}"
fi
}
echo -e "${YELLOW}Status procesów gry MT2SRV:${RESET}"
echo -e "game: $(color_status $COUNT_GAME)"
echo -e "db: $(color_status $COUNT_DB)"
echo -e "auth: $(color_status $COUNT_AUTH)"
Wyjaśnienie: Funkcja color_status przyjmuje liczbę procesów i zwraca tekst z informacją, czy procesy są uruchomione (zielony napis) lub nie (czerwony napis). Następnie wypisujemy status każdej aplikacji gry.
echo -e "${YELLOW}Szczegóły procesów game/db/auth:${RESET}"
ps aux | grep -E 'game|db|auth' | grep -v grep | awk -v GREEN="${GREEN}" -v RESET="${RESET}" '{print GREEN $0 RESET}'
Wyjaśnienie: Pokazujemy szczegóły działających procesów o nazwach zawierających "game", "db" lub "auth". Wynik jest kolorowany na zielono dla lepszej czytelności w terminalu.
Jak używać tego skryptu?
Skrypt zapisujemy jako plik wykonywalny, np. /etc/motd.sh. Nadajemy mu uprawnienia wykonania (chmod +x /etc/motd.sh) i wywołujemy go z pliku startowego powłoki, np. ~/.bash_profile lub globalnie w /etc/profile, dodając w nich linię:
/etc/motd.shDzięki temu podczas każdego logowania do powłoki pojawi się dynamiczny i kolorowy Message Of The Day z najważniejszymi informacjami o systemie i stanie procesów.